近日,智元机器人在科技领域投下了一枚震撼弹,正式推出了其首款通用具身基座模型——智元启元大模型Genie Operator-1(简称GO-1)。这一创新成果不仅标志着机器人在智能化道路上迈出了重要一步,更预示着具身智能将迎来前所未有的变革。

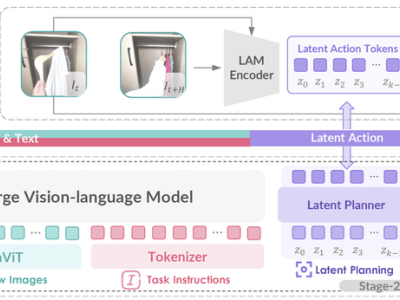
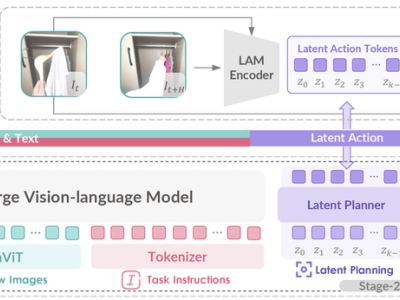
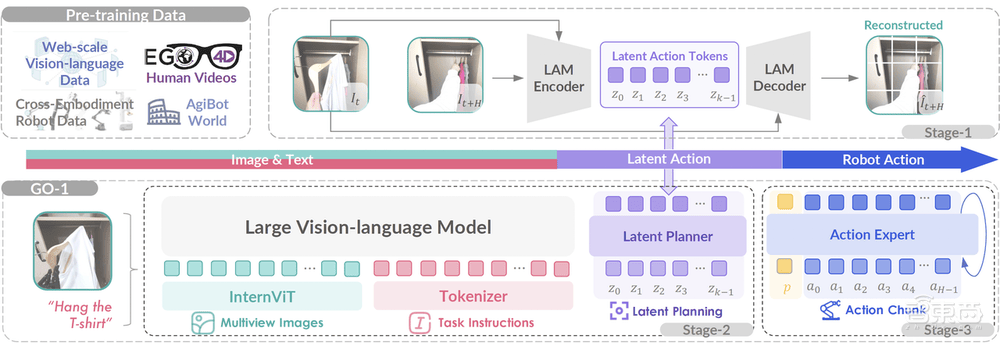
GO-1的核心在于其独特的Vision-Language-Latent-Action(ViLLA)框架,该框架由VLM(多模态大模型)与MoE(混合专家)两大组件构成。VLM作为主干网络,继承了开源多模态大模型的强大能力,通过大规模纯文本和图文数据的训练,赋予了GO-1出色的场景感知与理解能力。而MoE则进一步强化了GO-1的动作规划与执行能力,通过隐动作专家模型和动作预测器,实现了从视觉信号到动作执行的精准映射。
GO-1的推出,意味着机器人将不再局限于单一的任务或环境。其小样本快速泛化的能力,使得机器人能够在极少数据甚至零样本的情况下,快速适应新场景和新任务。这一特性,无疑为机器人的广泛应用提供了极大的便利。
更令人瞩目的是,GO-1还具备“一脑多形”的跨本体应用能力。这意味着,同一个GO-1模型可以轻松地迁移到不同形态的机器人上,实现快速适配。这一特性不仅降低了机器人的研发成本,更提高了机器人的灵活性和可扩展性。
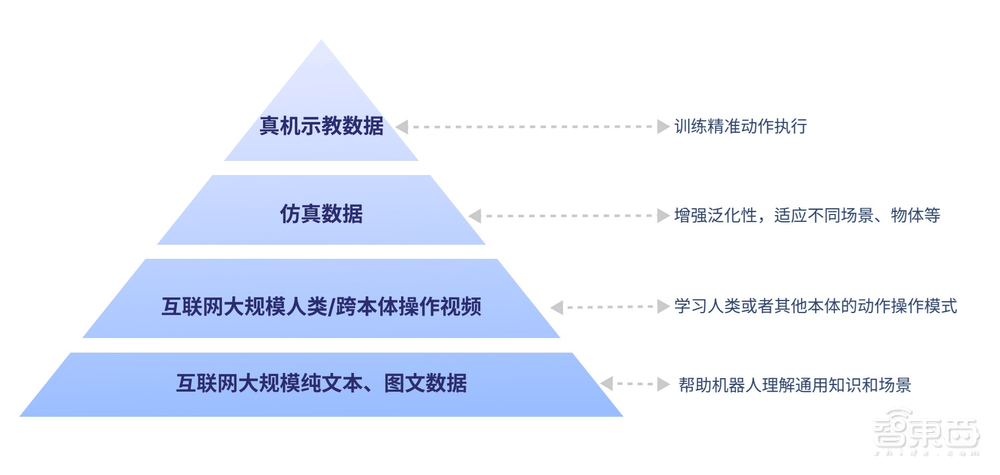
智元机器人还为GO-1构建了一个基于具身领域的数字金字塔,从底层的互联网大规模纯文本与图文数据,到上层的人类操作/跨本体视频,再到顶层的仿真数据和真机示教数据,形成了一个完整的知识体系。这一知识体系为GO-1提供了全面的“基础教育”和“能力培训”,使其能够轻松应对多种多样的环境和物体,快速学习新的操作。
在实际应用中,GO-1展现出了惊人的表现。无论是家庭场景中的准备餐食、收拾桌面,还是办公和商业场景中的接待访客、发放物品,GO-1都能轻松应对。GO-1还具备持续进化的能力,通过数据回流系统,可以从实际执行中遇到的问题数据中不断学习,不断提高自身的性能。
在商务会议中,GO-1更是大放异彩。面对人类发出的各种语音指令,如“帮我拿一瓶饮料”“帮我拿一个苹果”,GO-1都能迅速响应,准确执行。这一表现,无疑为机器人的广泛应用打开了新的篇章。


智元机器人还透露,未来几个月将推出基于强化学习的仿真模型,并计划推出新的人形机器人。这一消息,无疑为科技爱好者们带来了更多的期待。
GO-1的成功推出,不仅展示了智元机器人在机器人领域的深厚积累,更为具身智能的发展指明了方向。随着技术的不断进步和应用场景的不断拓展,相信GO-1将在更多领域展现出其强大的实力。