在机器人技术的前沿探索中,一款名为智元启元大模型Genie Operator-1(简称GO-1)的通用具身基座模型于近日震撼发布,标志着智能机器人领域迈入了一个全新的发展阶段。这款模型由智元机器人公司倾力打造,通过创新的Vision-Language-Latent-Action(ViLLA)框架,实现了多模态学习与混合专家系统的完美融合。
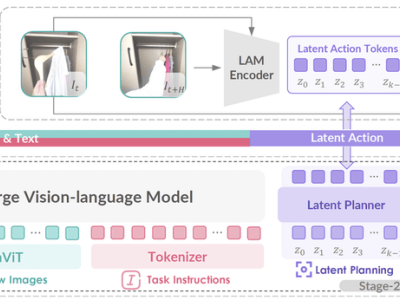
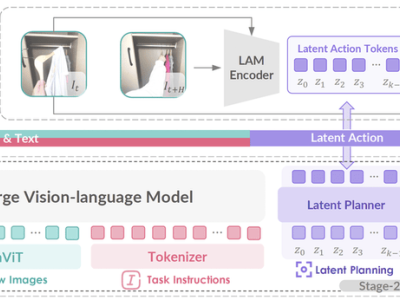
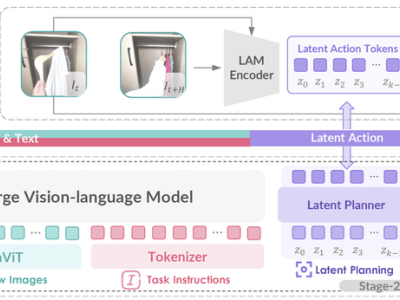
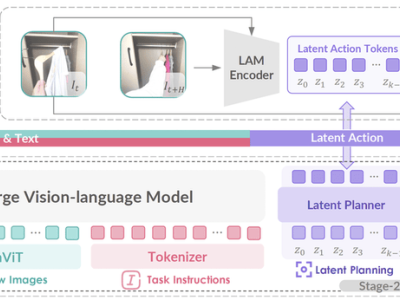
GO-1的核心竞争力在于其ViLLA框架,该框架由VLM(多模态大模型)与MoE(混合专家)两大模块构成。VLM作为模型的主干网络,基于开源多模态大模型5-2B的权重进行训练,借助互联网上的海量纯文本与图文数据,赋予了GO-1卓越的场景感知与理解能力。而MoE则通过隐动作专家模型和动作专家模型的协同作用,让机器人能够学习并理解人类操作模式,同时具备精细的动作执行能力。

GO-1的五大特点尤为引人注目:采训推一体化设计,使得数据采集、模型训练与推理过程无缝衔接;小样本快速泛化能力,使模型能够在极少数据甚至零样本的情况下快速适应新场景与新任务;一脑多形功能,让模型能够轻松迁移至不同形态的机器人本体;持续进化特性,依托智元的数据回流系统,模型能够不断从实际执行中遇到的问题数据中学习进化;人类视频学习能力,使模型能够通过互联网视频和真实人类示范进行学习,进一步提升对人类行为的理解。
在构建过程中,GO-1采用了具身领域的数字金字塔结构,从底层的大规模纯文本与图文数据,到人类操作与跨本体视频,再到仿真数据与高质量真机示教数据,形成了全面的知识库与技能库。这一结构使得GO-1能够轻松应对多种多样的环境和物体,快速学习新的操作。

ViLLA框架的引入,使得GO-1能够将多相机的视觉信号与人类语言指令直接转化为机器人的动作执行。与Vision-Language-Action(VLA)模型相比,ViLLA通过预测隐式动作标记(Latent Action Tokens),有效弥合了图像-文本输入与机器人执行动作之间的鸿沟。用户只需用自然语言向机器人发出指令,如“挂衣服”,GO-1便能根据所学知识与经验,拆解任务步骤,精准完成整个操作。

GO-1的应用场景广泛,从家庭场景中的准备餐食、收拾桌面,到办公和商业场景中的接待访客、发放物品,再到工业等更多领域的操作任务,GO-1都能快速实现。其强大的数据回流与持续进化能力,使得机器人在执行任务过程中不断积累经验,优化表现。例如,当机器人在制作咖啡时不慎将杯子放歪,它便能从这次失败中学习,并在未来的任务中避免类似错误。