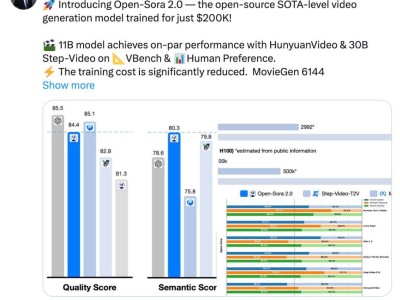
近期,全球科技界迎来了一项重要突破:DeepSeek开源的3FS系统通过优化存储,显著提升了AI推理工作负载的性能,同时大幅度降低了成本。这一创新成果引发了业界的广泛关注。

3FS系统作为AI原生存储,凭借其链式复制机制和FFRecord格式优化等独特设计,不仅刷新了AI存储的技术标准,更彰显了专用存储系统在支撑超大规模模型推理中的关键作用。这一系统的推出,标志着AI存储技术迈上了新的台阶。
从技术层面来看,曙光存储ParaStor与3FS在推动AI基础设施的进化上展现出高度的一致性。两者都是高性能并行文件系统的杰出代表,专为AI数据存储而设计。
以RDMA技术为核心传输协议,曙光ParaStor和3FS通过零拷贝机制将网络延迟降至微秒级,有效解决了传统TCP/IP协议栈在AI集群中引发的CPU资源争用问题,使得200Gbps网卡的利用率得以突破90%。在此基础上,两者还引入了硬件卸载技术,将数据校验和协议解析等任务交由智能网卡处理,从而进一步提升了性能。
实测数据显示,硬件卸载技术的引入使得存储读响应时间缩短了40%,同时释放了30%以上的CPU算力用于模型推理。这种“存储即服务”的设计理念,打破了传统存储依赖CPU资源的模式,为AI集群提供了更多的算力空间。
针对AI训练特有的小文件高并发、数据访问局部性及混合负载特性,曙光存储ParaStor和3FS都构建了多层次优化体系。通过元数据分片技术,两者将海量小文件的元数据请求分散到多个控制节点,从而显著提升了查询吞吐量,支持了万级客户端的并发访问。智能预取与缓存分层技术通过分析训练任务的数据访问模式,提前将数据从HDD预加载至NVMe缓存,有效缩短了ResNet-152单epoch的训练时间。
为满足大模型训练对海量数据的需求,曙光存储ParaStor与3FS均采用了去中心化架构。通过全局命名空间技术,两者整合了跨地域、跨介质的存储资源,支持了千亿文件的统一管理。无状态弹性扩展技术使得节点可以在线扩展至数千个,容量与性能随节点增加而线性提升。在GPT-3级场景中,两者均实现了超过1TB/s的聚合带宽。
曙光ParaStor和3FS还采用了自适应纠删码策略,对热数据采用多副本保障性能,对温冷数据采用EC 8+3编码,从而提升了空间利用率。这一策略使得存储系统的空间利用率突破了85%。
曙光ParaStor在国产化创新方面取得了显著成果。依托国产硬件生态优势,曙光ParaStor实现了自研SSD控制器与智能网卡的协同优化,在国产AI芯片适配性上展现出独特价值。这种自主可控的技术路径不仅提升了系统的稳定性与安全性,更为我国AI产业的快速发展提供了坚实的基础设施保障。
3FS的技术突破与曙光ParaStor的国产化创新共同表明,硬件加速、场景化优化与分布式架构的深度融合是突破“存储墙”的关键路径。这一行业共识的达成,将进一步推动AI存储技术的创新与发展。
在共性技术之外,曙光ParaStor还凭借其独特的自主可控技术路径,在国产AI芯片适配性上展现出显著优势。这一优势不仅提升了系统的整体性能,更为我国AI产业的自主可控发展提供了有力支撑。