在人工智能(AI)技术迅猛发展的当下,企业正面临一场数据治理的革命。业务部门渴望通过数据驱动决策,却常常因为指标口径的不统一和数据血缘的不透明而陷入困境。同时,技术团队在投入大量资金训练AI模型时,也往往因基础数据质量的问题而导致事倍功半。这一现状迫使企业不得不重新审视数据治理的价值。
在近期于上海举办的「数据荟」Meet Up活动中,阿里云智能集团瓴羊的高级技术专家周鑫指出,数据治理实施的最大难题在于治理过程涉及的点过多,导致企业在多个治理模块中疲于奔命,难以形成持续的价值。他提出,以数据标准为中心,贯穿数据全生命周期,是破解这一困局的关键。
数据治理之所以困难重重,是因为实施链路复杂且繁琐。企业在进行数据治理时,通常需要经历现状评估、目标制定、计划执行和持续监控等多个步骤。在这个过程中,企业不仅要考虑数据质量、数据安全和生命周期管理,还要在控制成本的同时,兼顾整个组织架构的需求。周鑫表示,传统的治理步骤面临实施方法复杂、治理链路繁琐、工具支撑不足和难以持续治理等四大问题。

这一困境导致企业在实施数据治理时容易偏离中心,缺乏一个核心抓手。即使艰难完成治理,后续的迭代也非常困难,因为任何一个目标的改动都可能牵一发而动全身,导致数据安全与质量规则的反复调整,大大拖慢了治理进度。因此,找到数据治理的核心——数据标准,成为了解决问题的关键。
近年来,国家频频出台数据标准相关政策规范,从《“数据要素x”三年行动计划》到国家数据标准体系,再到全国数据标准化技术委员会,都彰显了数据标准的重要地位。周鑫表示,当企业确定了数据标准,治理工作就已经完成了很大一部分。以瓴羊Dataphin为例,企业完成业务与数据盘点后,将数据纳入数据元中心,便可以在Dataphin中梳理数据标准。数据标准的建立不仅贯穿数据建模、研发等事前环节,还能通过生成质量规则和安全识别、分类分级等功能,实现对数据事中及事后的全面管控。
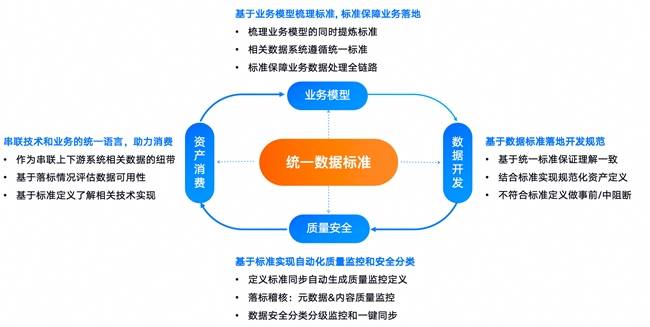
在数据标准的基础上,企业可以更加高效地管理数据质量。例如,在手机号的标准设置中,系统会自动根据用户设定的属性要求生成一系列质量校验规则,确保相关字段数据符合标准。在访问权限上,系统也会自动匹配审批流程,帮助快速识别和处理不合规的数据。这使得数据标准的满足度成为衡量数据质量优劣的重要指标。
AI技术的爆发为数据治理带来了新的机遇。周鑫认为,通过AI与数据治理的结合,可以实现完整的主动数据治理。在数据标准阶段,AI可以逆向生成码表、数据标准和数据模型,大大降低从业务到标准、到模型的实施成本。同时,AI还能自动识别治理效果,提供治理策略指引,形成数据治理的良性内循环。

瓴羊Dataphin的实践展示了AI在数据治理中的巨大潜力。通过智能小D平台,用户可以直接通过对话的方式询问具体的业务需求,系统会根据用户需求快速提供对应的数据资产表。Dataphin还引入了AI能力来丰富数据属性、简化数据上架流程以及加快特征识别速度。这使得企业能够更加高效地管理和使用数据资产。
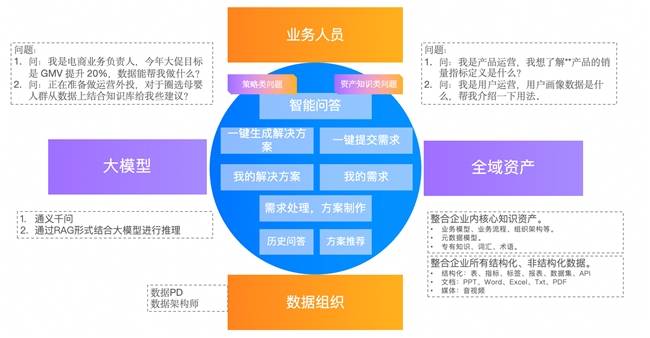
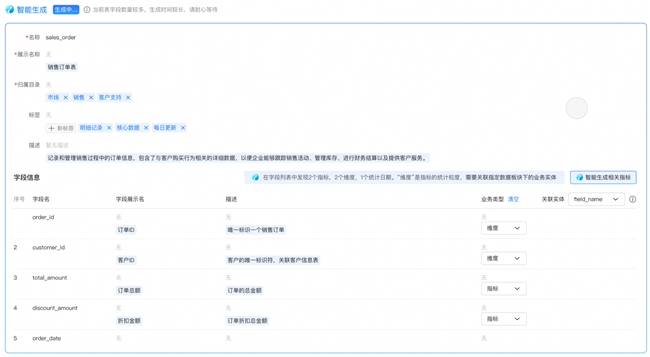
周鑫还介绍了Dataphin在数据治理与AI融合方面的远期规划。他提出,迈向智能化的最大标志是自助治理,即通过AI能力基于业务变化自动调整治理目标、策略和业务动作。面对海量数据质量参差、治理链路冗长的挑战,他建议从小的业务和领域切入,通过缩小问题求解集合来加快提升数据质量。随着AI技术的不断发展,Dataphin将实现对业务流程的深度理解,系统自动生成数据标准,全面提升数据治理的智能化水平。