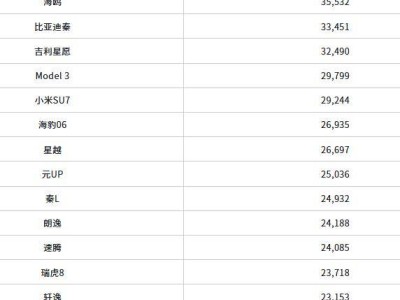
近年来,自动驾驶技术的竞争风向发生了显著变化。过去,厂商们竞相展示芯片算力和激光雷达的数量,但如今,消费者已逐渐认识到,硬件的堆砌与实际的智能驾驶能力并不成正比。例如,曾高调宣称需要“4颗激光雷达”的机甲龙项目已黯然退场,而搭载4颗英伟达Orin芯片、总算力高达1016 TOPS的蔚来ET7也未能引起广泛关注。
从去年开始,业界关注的焦点迅速从硬件转向了软件。相较于直观可见的硬件,软件的宣传更为晦涩难懂,让外行人难以捉摸。为了帮助消费者更好地理解,以下是四个在自动驾驶领域频繁出现的专业术语,了解它们,或许能让你从“门外汉”变身“专家”。
首先,“端到端”(E2E)这一自动驾驶算法范式,由特斯拉率先实践并取得成功,随后被众多企业跟进,成为业内的主流方向。简单来说,端到端自动驾驶算法模拟人脑神经元的工作方式,将感知信息输入模型的一端,另一端则直接输出轨迹或控制信号,实现了驾驶行为的“无缝衔接”。相较于传统的模块化架构,端到端能够减少信息的损失和人为偏见,大幅提升智能驾驶的能力上限。然而,长安汽车的首席智能驾驶技术官陶吉指出,尽管端到端学习是通往终极自动驾驶的必要一步,但它并非充分条件。

随着技术的不断进步,端到端算法模型的门槛已大幅降低。小马智行的CTO楼天城表示,目前训练一个具有一般性能的端到端模型已不再是难题。这也解释了为何众多车企一夜之间都推出了自研的端到端智能驾驶系统。但需要注意的是,端到端本身是一个架构层面的概念,与模仿学习、强化学习等技术手段并不在同一层面。因此,即使在相同的架构下,不同厂商的系统表现也可能大相径庭。
接下来是D2D,即“从出发车位泊出到目的地车位泊入”的全场景自动驾驶功能。随着高阶智能驾驶的普及,市场竞争已从“人无我有”转变为“人有我优”。如今,各家车企都在强调智能驾驶的体验和易用性,追求实现“车位到车位、门到门”的全场景智能驾驶体验。D2D已成为衡量端到端性能的关键指标之一。目前,华为、理想、小米、极氪等企业已开始分批推送D2D功能。
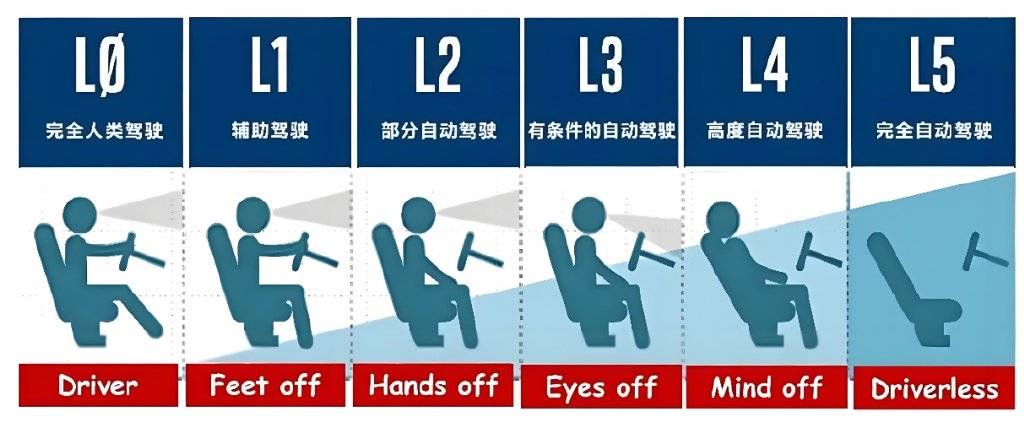
在D2D功能的实现上,不同企业采取了不同的路径。以理想为例,其采用的是“记忆泊车+智驾领航+记忆泊车”的技术路径,在停车场路段使用记忆泊车模式,驶入公开道路后则转变为智驾领航模式。而特斯拉和小鹏则采用了一套模式打通全场景,无论是在园区封闭路段还是公开路段,都保持智驾NOA画面不变,注重智驾应对复杂路况的连贯性和完整性。
再来看VLM,即视觉语言模型,是LLM(大语言模型)的进阶版,可将视觉信息与自然语言文本联系起来。在自动驾驶领域,VLM能够识别道路环境、交通标志等,并通过大量训练理解交通场景中的复杂交互事件,为自动驾驶系统提供决策支持。在国内,理想是第一家将VLM概念引入自动驾驶的车企。它采用了双系统方案,系统1(端到端模型)完全依赖视觉感知执行操作,系统2(VLM)则提供复杂环境的理解能力等,辅助系统1进行规划决策。
然而,也有企业认为VLM的算力和功能之间的投入产出比不够高,是一个过渡阶段。未来,真正的换代升级将是VLA,即视觉-语言-动作模型。VLA是在VLM的基础上发展而来的多模态机器学习模型,可以提取丰富的环境信息,理解人类指令并生成可解释的决策过程。与传统的VLM相比,VLA不仅能解析图像和文本信息,还能实现类人推理与全局理解。
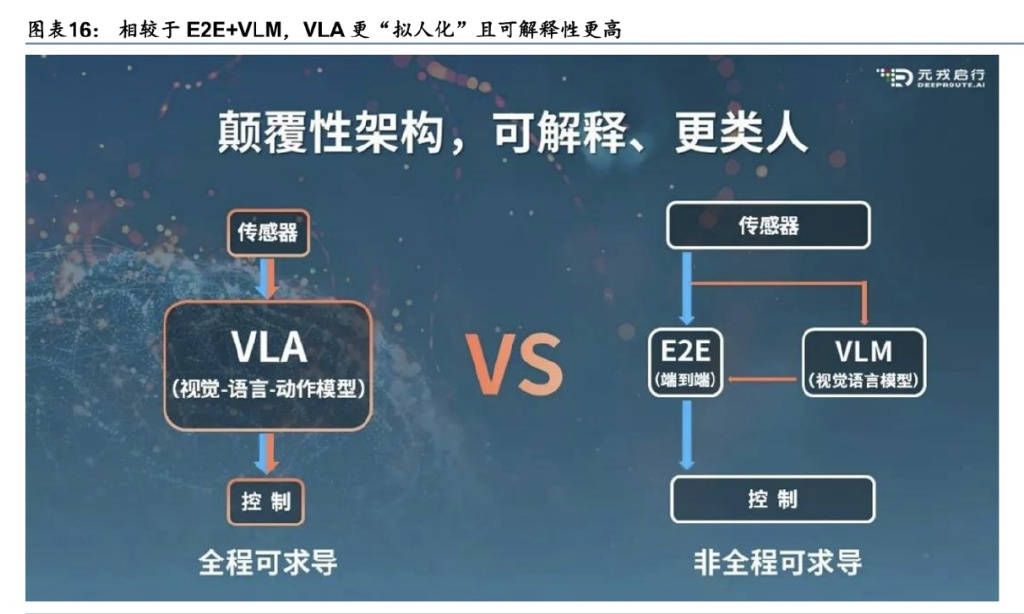
据元戎启行的CEO周光介绍,VLA模型在面对复杂的交通规则、潮汐车道等特殊场景时,能够比以往的系统更好地理解和应对。例如,在推理时长方面,传统的基于规则方案只能推理1秒钟的路况信息,而VLA模型则能够对几十秒的路况进行推理,显著提升了自动驾驶系统的决策能力和适应性。目前,理想已开始研发下一代VLA智能驾驶大模型,吉利汽车和元戎启行也在积极推动VLA技术的落地。