在科技界的聚光灯下,英伟达CEO黄仁勋于GTC 2025大会上再度成为焦点。尽管近期英伟达股价遭遇重创,触及十年低点,但黄仁勋依旧以一身标志性的皮衣亮相,信心满满地展示着公司的最新GPU技术。
回顾今年二月,DeepSeek的横空出世在AI领域掀起了波澜。这一由中国团队打造的产品,仅凭少量低端GPU(以A100为主)便成功“蒸馏”出高端GPU(如H100)级别的性能,令业界哗然。一时间,“规模定律”(Scaling Law)的传统观念受到挑战,即模型参数量、数据集大小和训练成本不再被视为越多越好。过去,谷歌、meta、微软等科技巨头不惜重金采购H100芯片,以期在算力上占据优势。而今,DeepSeek的出现似乎打破了这一僵局,使得无需庞大算力也能训练出媲美OpenAI GPT的大模型。
网络上关于DeepSeek或将导致英伟达走向衰落的言论甚嚣尘上,尤其在海外社交媒体上,此类观点迅速传播。有网友直言“英伟达的一切都将开始瓦解”,这一期间,英伟达的股价频繁出现大幅下跌,单日跌幅达13%、17%已不足为奇。
然而,另一种声音则认为,从长远来看,DeepSeek的成功反而对英伟达有利。毕竟,DeepSeek虽降低了训练大模型的门槛,但仍需计算卡支持。A100计算卡,正是英伟达的产品之一。随着入场玩家增多,市场对算力的总体需求或将上升,英伟达作为全球最大的GPU供应商,有望售出更多计算卡。训练超大模型仍需H100等高性能计算卡集群,这似乎陷入了一个“先有鸡还是先有蛋”的循环。
在GTC 2025大会上,黄仁勋终于亲自回应了DeepSeek带来的冲击。他首先对DeepSeek表示赞赏,称其为“卓越的创新”和“世界级的开源推理模型”,并不解为何外界会将DeepSeek视为英伟达的威胁。
针对Scaling Law的讨论,黄仁勋提出了自己的见解。他将Scaling Law细分为预训练(PRE-TRAINING SCALING)、后训练(POST-TRAINING SCALING)和测试时缩放(TEST-TIME SCALING)三个阶段,强调随着AI的发展,对算力的需求将持续增长。他提出,AI的发展分为感知人工智能、生成式人工智能、代理人工智能和未来物理AI四个阶段,当前正处于代理人工智能阶段,对算力的需求尤为迫切。
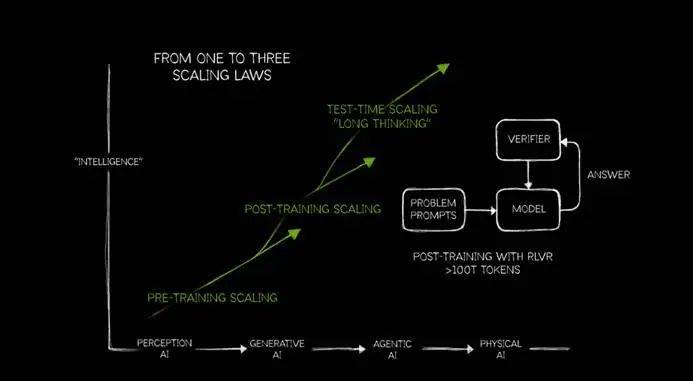
黄仁勋指出,推理模型在运行时,token的消耗量激增。他比喻道,不仅需要提升token的吞吐量十倍,还需过去十倍的算力来加速token的输出,最终所需算力将是原先的百倍。相较于传统的生成式模型,推理式模型如DeepSeek R1,在推理过程中会消耗更多token,这成为算力需求增长的关键因素。
事实上,英伟达GPU的销量并未因DeepSeek的出现而下滑。据彭博社报道,OpenAI计划在“星际之门”项目中建立一个可容纳40万个英伟达AI芯片的数据中心,这将是全球最大的AI算力集群之一。马斯克旗下的xAI、meta以及国内的阿里、小米、腾讯等公司也在积极部署算力,而这些公司的显卡供应商大多是英伟达。在个人本地部署领域,DeepSeek R1虽然降低了训练门槛,但对算力的要求依旧不低,高性能硬件仍是提高推理速度的关键。
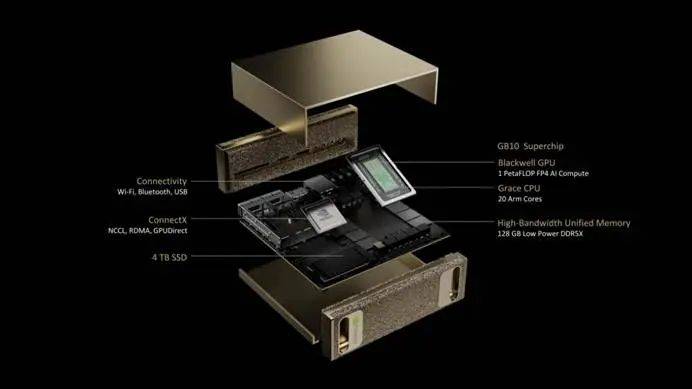
英伟达推出的DGX Spark虽然定位为可用于本地部署的AI电脑,但其性能却令人不敢恭维。其128GB内存和273GB/s的带宽,对于运行大多数32B模型来说,推理速度可能只能达到2-5 tokens/s,难以满足推理模型的需求。这或许意味着,DGX Spark的存在更多是为了衬托更强大的DGX Station。
英伟达在GPU领域的领先地位依旧稳固,但真正缺乏的是对消费者的诚意。面对市场的变化和挑战,英伟达需要拿出更多具有诚意的产品,而非仅仅依靠贩卖焦虑来维持投资者的信心。