OpenAI近期在语音技术领域取得了显著进展,于3月20日正式宣布推出全新的语音转文本及文本转语音模型,这一举措旨在增强语音处理能力,并为开发者提供更加精确和可定制化的语音交互系统解决方案,进一步推动人工智能语音技术的商业化落地。
在语音转文本方面,OpenAI推出了两款重量级模型:gpt-4o-transcribe和gpt-4o-mini-transcribe。据官方介绍,这两款模型在单词错误率、语言识别准确性和性能方面,均超越了现有的Whisper系列模型。它们能够支持超过100种语言的识别,通过强化学习和多样化的高质量音频数据集进行训练,有效捕捉语音中的细微特征,显著减少了误识别率。特别是在嘈杂环境、口音差异以及不同语速下,这两款模型表现出了更加稳定和出色的性能。

对于文本转语音领域,OpenAI推出了gpt-4o-mini-tts模型。这款模型允许开发者通过指令控制语音风格,如“模拟耐心客服”或“生动故事叙述”,从而满足多样化的应用场景需求。在客服领域,gpt-4o-mini-tts能够合成更具同理心的语音,提升用户体验;在创意内容方面,它则能够为有声书或游戏角色设计个性化声音,带来更加丰富和生动的听觉体验。
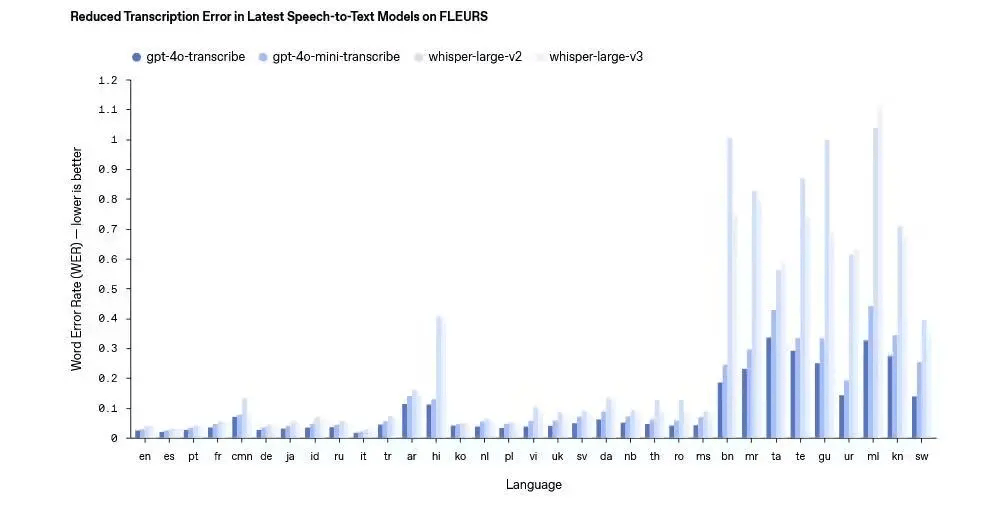

OpenAI在发布的博文中还详细公布了这三款模型的费用情况。gpt-4o-transcribe模型对于音频输入、文本输入和输出的费用分别为每100万tokens 6美元、2.5美元和10美元,每分钟成本为0.6美分。相比之下,gpt-4o-mini-transcribe模型则更加经济实惠,音频输入、文本输入和输出的费用分别为每100万tokens 3美元、1.25美元和5美元,每分钟成本为0.3美分。而gpt-4o-mini-tts模型的费用则为每100万tokens输入0.6美元,输出12美元,每分钟成本为1.5美分。
此次OpenAI推出的全新语音转文本和文本转语音模型,不仅提升了语音技术的性能和准确性,还为开发者提供了更加灵活和多样化的应用方案。随着人工智能技术的不断发展,这些模型有望在更多领域得到广泛应用,推动人工智能语音技术的进一步普及和商业化。