在自动驾驶技术的浪潮中,正当特斯拉专注于FSD系统的迭代优化之时,中国的造车新势力已经悄然掀起了一场智能驾驶领域的范式革命。在NVIDIA GTC 2025大会上,理想汽车自动驾驶技术的领军人物贾鹏,隆重介绍了MindVLA架构,这一创新成果不仅突破了传统驾驶技术的桎梏,更是在人工智能与自动驾驶物理智能体的融合探索上,树立了全新的行业标杆。

MindVLA架构究竟有何独到之处?贾鹏详细阐述道:“MindVLA是一个集空间智能、语言智能和行为智能于一体的机器人大模型。一旦成功实现物理世界与数字世界的无缝对接,它将有望为众多行业带来革新。更重要的是,MindVLA将汽车从单纯的交通工具,转变为能够‘听懂’、‘看见’、‘找到’的贴心专职司机。我们期望通过MindVLA,赋予汽车类似人类的认知和适应能力,使之成为真正能够思考的智能体。”
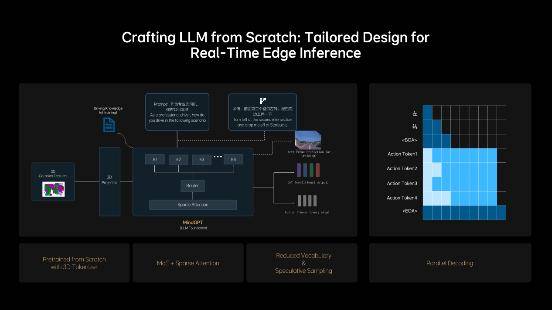
在技术上,MindVLA打破了自动驾驶的传统框架,引入了3D高斯(3D Gaussian)作为中间表征,这种表征不仅具有丰富的语义信息,还具备出色的多粒度、多尺度3D几何表达能力。通过海量数据的自监督训练,MindVLA极大提升了下游任务的性能。理想汽车从零开始,设计和训练了专为MindVLA打造的LLM基座模型,采用MoE混合专家架构和Sparse Attention技术,实现了模型的稀疏化,从而在模型规模增长的同时,保证了端侧的推理效率。
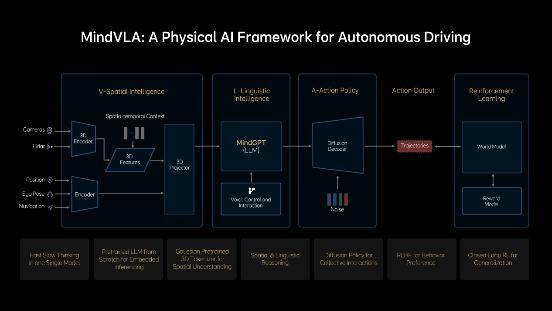
在LLM基座模型的基础上,理想汽车进一步提升了其逻辑推理能力。通过训练模型学习人类的思考过程,实现了快慢思考的有机结合,并可根据需要自主切换。为了充分发挥NVIDIA Drive AGX的性能,MindVLA采用了小词表结合投机推理,并创新性地应用了并行解码技术,从而实现了模型参数规模与实时推理性能之间的完美平衡。
MindVLA在复杂交通环境中的博弈能力同样令人瞩目。它利用Diffusion技术将Action Token解码成优化的轨迹,并通过联合建模自车行为生成和他车轨迹预测,显著提升了应对复杂交通环境的能力。MindVLA还采用了Ordinary Differential Equation(常微分方程)采样器,仅需2-3步即可生成高质量的轨迹。与特斯拉的纯视觉方案相比,MindVLA通过重建与生成的云端世界模型,构建了虚实交融的训练环境,实现了从错误中学习的强化闭环。这一技术路径的差异,将智能驾驶从“数据驱动”提升到了“认知驱动”的新高度。
在用户感知层面,MindVLA带来的变革远不止技术参数的提升。它重构了人车交互的范式,成为了用户真正“听得懂”、“看得见”、“找得到”的专职司机。无论是理解“带我去找超市”这样的语义指令,还是通过识别商店招牌并自主寻人,甚至在无地图支持的情况下完成空间推理,MindVLA都展现出了惊人的能力。它不再只是一个驾驶工具,而是一个能够与用户沟通、理解用户意图的智能体,这种转变将重新定义智能驾驶的竞争格局。

相关行业专家指出,MindVLA所展现出的跨场景适应能力,有望为智能驾驶的商业化开辟新的蓝海。它在各个场景中的突破,实质上是将L4级技术的应用场景从限定区域扩展到了更广泛的场景。正如iPhone 4重新定义了手机一样,MindVLA也将重新定义自动驾驶,为行业探索出一条兼顾性能与效率的全新路径。