腾讯近日宣布,其自研的混元大模型系列中的深度思考模型——混元-T1,已正式升级至T1正式版。这一消息标志着腾讯在人工智能领域的又一次重要技术突破。

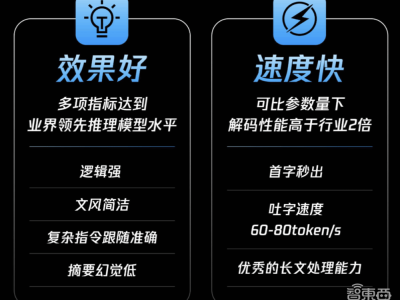
据了解,混元-T1是腾讯自研的一款强推理模型,其吐字速度高达每秒60至80个token,在实际生成效果上远超此前的DeepSeek-R1。该模型的前身,是今年2月中旬在腾讯元宝APP上线的混元T1-Preview推理模型。而此次升级,则是基于腾讯混元3月初发布的业界首个超大规模Hybrid-Transformer-Mamba MoE大模型TurboS快思考基座,通过大规模后训练,进一步扩展了推理能力,并对齐了人类偏好。
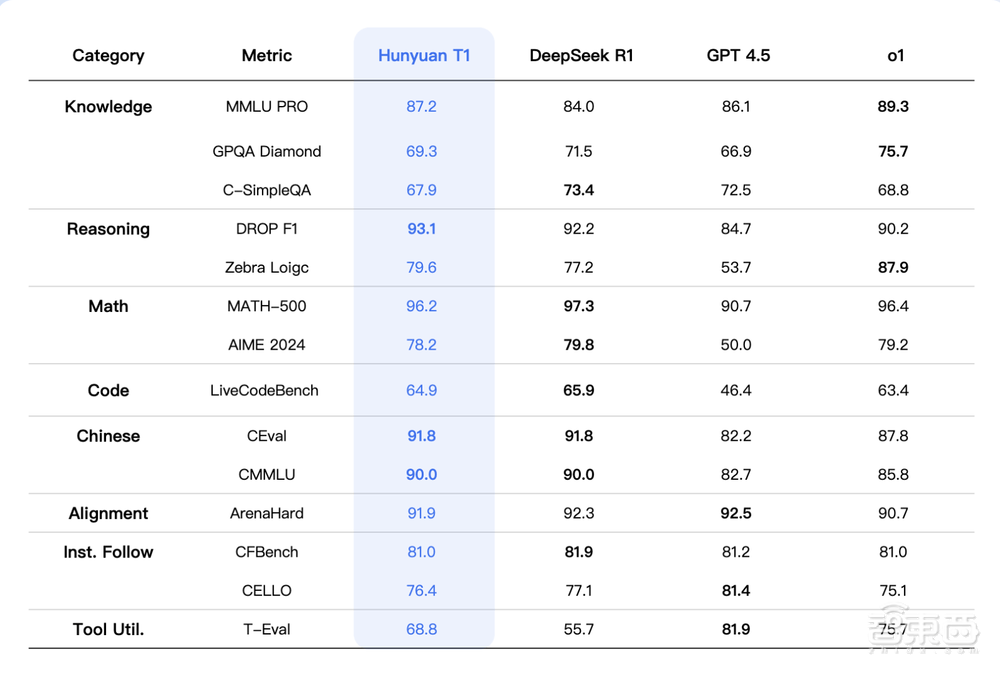
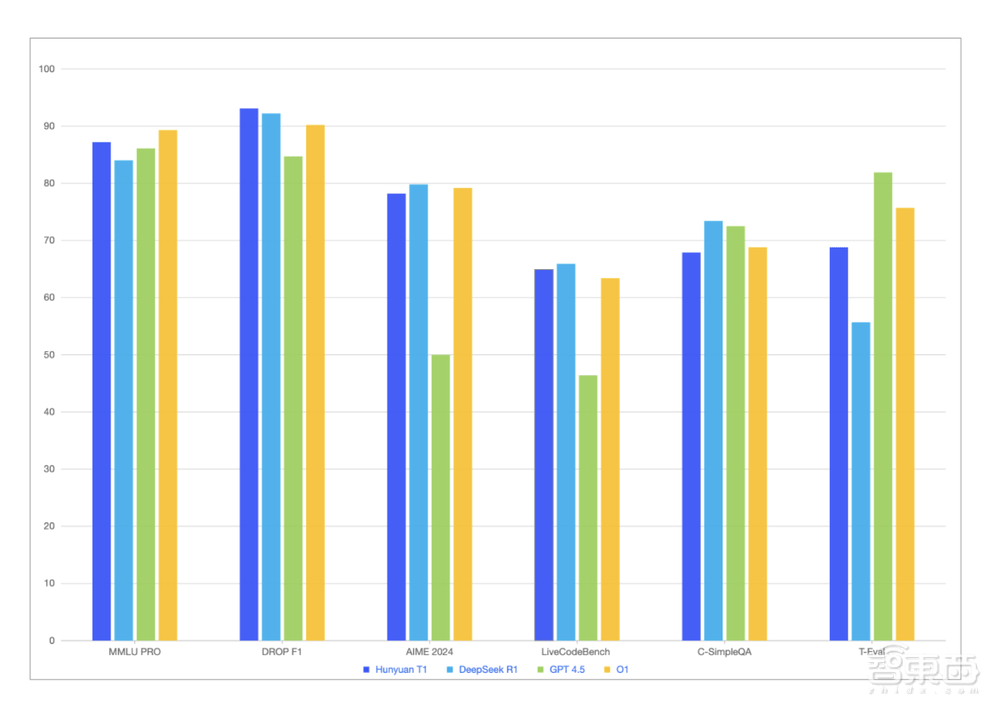
在多个公开数据集的评测中,混元-T1在MMLU-pro、Ceval、AIME、Zebra Logic等中英文知识和竞赛级数学、逻辑推理指标上,均表现出与R1持平或略超的水平。该模型在腾讯内部人工体验集评估中,也在文创指令遵循、文本摘要、Agent能力方面略胜一筹。
在知识问答场景中,腾讯混元研究团队展示了T1与DeepSeek的生成效果对比。无论是面对“醋酸乙酯能与水混合吗”这类简单问题,还是更为复杂的理科数学推理问题,T1都能迅速给出准确答案,且速度远超DeepSeek-R1。T1还展现出了强大的复杂指令跟随能力,如根据上联“深深浅浅溪流水”对出下联“洋洋洒洒波涛涌”,以及生成符合要求的朋友圈文案等。

混元-T1还具备出色的长文总结摘要能力。在针对微软收购暴雪的新闻报道进行摘要时,T1不仅准确总结了文章的主要内容,还提炼出了多个关键数字,展现了其作为生产力工具的巨大潜力。T1的角色扮演能力也令人印象深刻,如扮演李白猜字谜并赋诗一首,充分展示了其丰富的文化底蕴和创造力。
从技术角度来看,混元-T1正式版沿用了混元Turbo S的创新架构,采用Hybrid-Mamba-Transformer融合模式,这是工业界首次将混合Mamba架构无损应用于超大型推理模型。这一架构不仅降低了传统Transformer架构的计算复杂度,减少了KV-Cache内存占用,还降低了训练和推理成本。在长文本推理方面,TurboS的长文捕捉能力有效解决了上下文丢失和长距离信息依赖难题,使得模型在相同部署条件下解码速度更快。
在模型后训练阶段,腾讯混元研究团队将大部分算力投入到强化学习训练中,重点提升纯推理能力和对齐人类偏好。通过收集复杂指令多样性和不同难度分级的数据,并采用课程学习的方式逐步提升数据难度,同时阶梯式扩展模型上下文长度,使得模型在推理能力提升的同时学会高效利用token进行推理。研究团队还采用了经典强化学习的数据回放、阶段性策略重置等策略,提升了模型训练的长期稳定性。