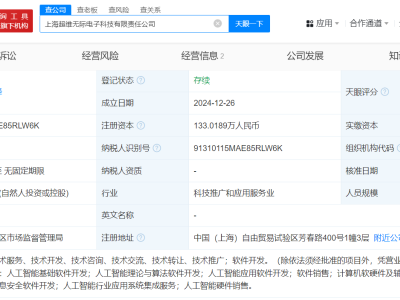
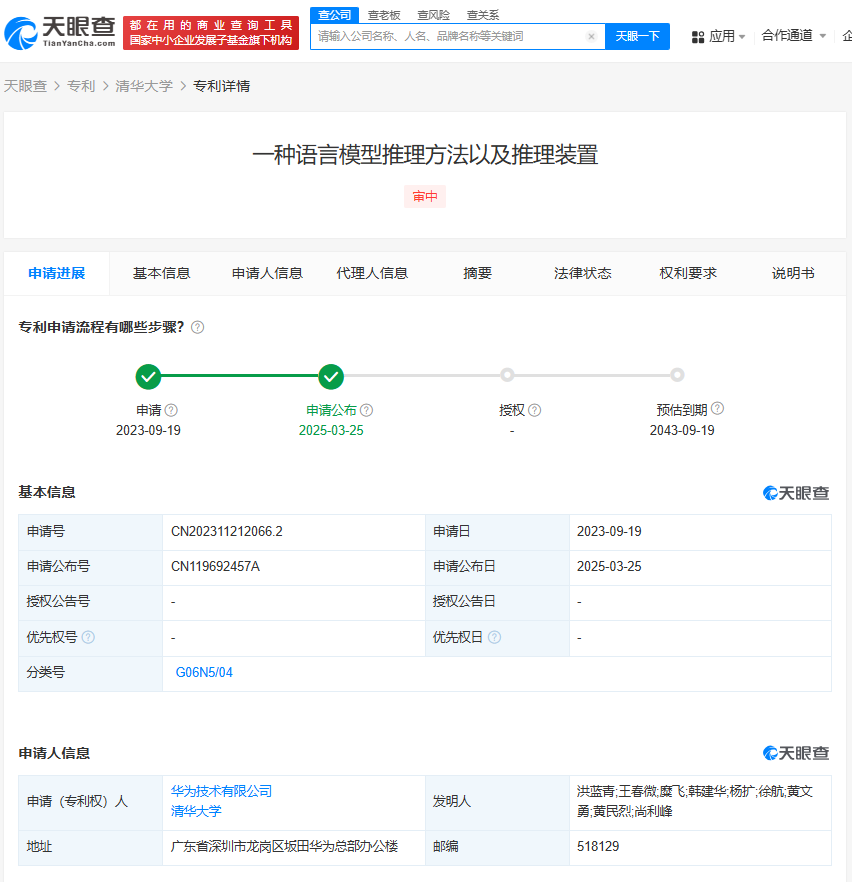
近期,一项由华为技术有限公司与清华大学联手申请的专利引起了广泛关注。据天眼查信息显示,这项名为“一种语言模型推理方法及其推理装置”的专利于3月25日正式公布。
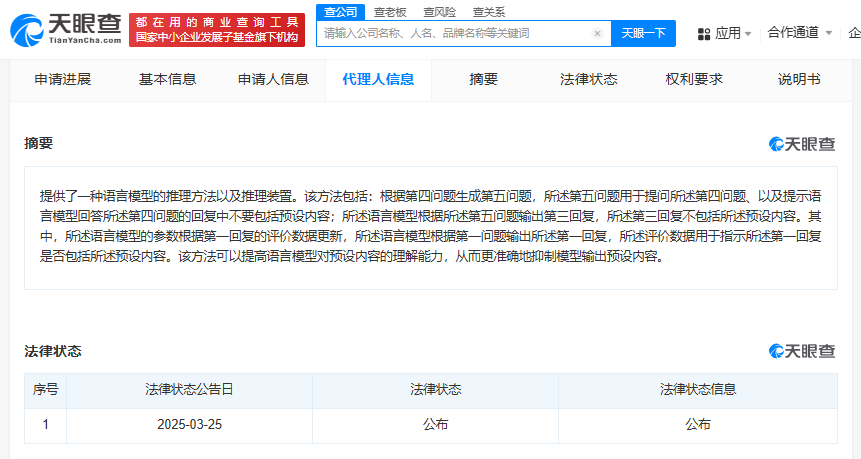
该专利的核心在于一种创新的语言模型推理方法,其具体操作流程颇具匠心。首先,系统会基于一个初始问题(第四问题)生成一个变形问题(第五问题)。这个第五问题不仅包含了原始问题的全部信息,还特别指示语言模型在回答时避免包含某些预设内容。随后,语言模型会根据这个经过精心设计的第五问题输出回答(第三回复),而这个回答会严格遵循指示,不包含任何预设内容。
更为先进的是,这个语言模型的参数并非一成不变,而是会根据过往回答的评价数据进行动态调整。具体来说,模型会先根据一个问题(第一问题)输出一个回答(第一回复),然后这些回答会根据是否包含预设内容等标准进行评价。这些评价数据将作为反馈,用于优化模型的参数,从而提升其理解和抑制预设内容的能力。
这项专利的公布,标志着华为与清华大学在人工智能领域的又一次深度合作取得了重要成果。通过这种方法,语言模型能够更加精准地理解和处理信息,避免在回答中包含不必要或敏感的内容,从而极大地提升了模型的实用性和准确性。
这项专利的推出也反映了当前人工智能领域对于语言模型推理能力的重视。随着技术的不断进步和应用场景的日益丰富,对于语言模型的理解能力、推理能力和控制能力都提出了更高的要求。而华为与清华大学的这项创新成果,无疑为这一领域的发展注入了新的活力和动力。
未来,随着这项专利的进一步应用和推广,我们有理由相信,语言模型将在更多领域发挥更大的作用,为人类社会的智能化进程贡献更多的智慧和力量。