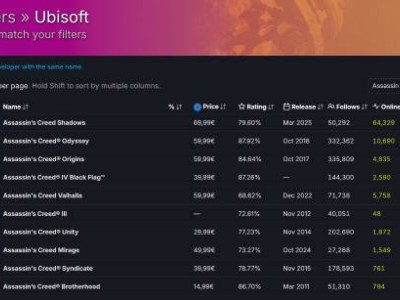
近期,OpenAI发布了一份事故报告,揭示了其对话补全API存在高错误率的问题,并承诺将尽快采取措施解决这一问题。与此同时,Sora图像生成的问题也已被解决,目前正处于持续监控状态。
在周二深夜的直播中,OpenAI带来了一则令人振奋的消息:GPT-4o的原生图像生成功能迎来了重大升级。OpenAI的首席执行官Sam Altman亲自上阵,与团队一起演示了诸多新功能,包括将自拍转化为梗图、创作相对论漫画等。
此次升级中,ChatGPT首次引入了图像生成功能。在GPT-4o这一旗舰多模态模型的支持下,用户现在可以直接在聊天界面中创建视觉效果,这一创新无疑为ChatGPT增添了更多趣味性和实用性。
据了解,这一新功能将首先向ChatGPT Plus、Pro、Team和免费用户开放,企业和教育级用户也将很快获得访问权限。Sam Altman在直播开始时难掩激动之情,他表示:“今天,我们推出了有史以来最有趣、最酷的产品之一——ChatGPT中的原生图像。”
Altman还承认,这一功能备受期待,尤其是在竞争对手如Google Gemini等自2024年中期以来就已经提供了集成图像生成功能的情况下。ChatGPT此次的升级,无疑是对市场需求的积极响应。
现在,ChatGPT允许用户根据提示、对话和上传的文件生成图像。无论是创建全新的图像还是转换现有图像,用户都可以轻松实现。GPT-4o模型中的世界知识训练使得ChatGPT能够更好地理解图像的使用环境,从而生成更加符合用户需求的图像。
ChatGPT还能更好地按照提示在图像中呈现文本。用户可以通过用自然语言提示模型来优化图像,例如在设计视频游戏角色时,模型可以在用户进行调整的过程中保持视觉一致性,并在多次迭代中不断优化。