近期,科技界迎来了一则重磅消息,谷歌正式揭晓了其Gemini思考模型家族的最新力作——Gemini 2.5 Pro实验版。这款模型一经面世,便以卓越表现震惊业界,在多项基准测试中力压群雄,包括OpenAI的o3-mini、Claude 3.7 Sonnet、Grok-3及DeepSeek-R1,以1443分的高分荣登大模型竞技场榜首,领先第二名多达39分。
值得注意的是,尽管Gemini 2.5 Pro在多项测试中展现出强大实力,但谷歌并未提供它与OpenAI更早版本模型,如o1、o1-Pro及o3的直接对比数据。在智能体编程评估基准SWE-bench verified上,它的表现略逊于Claude 3.7 Sonnet。
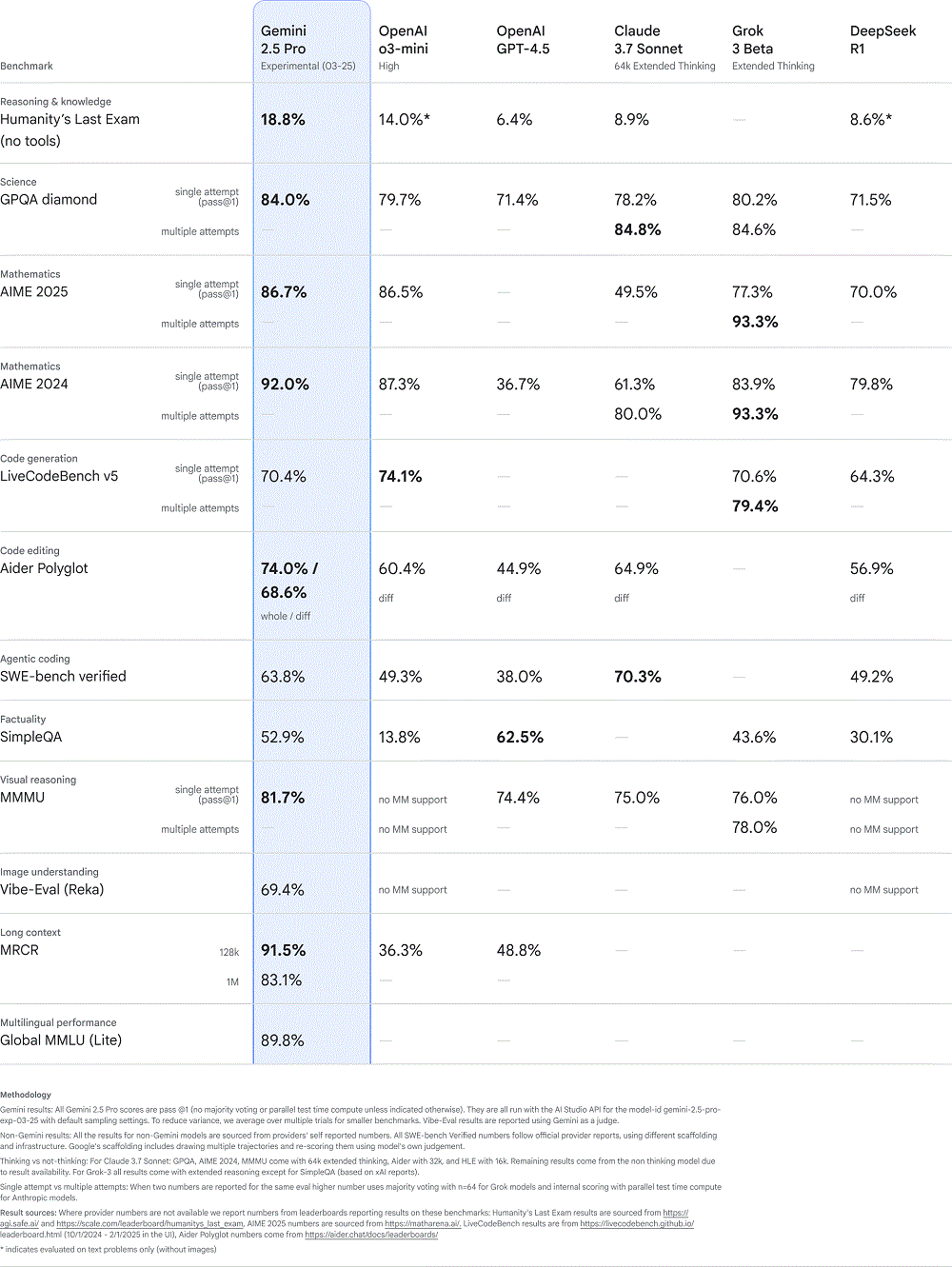
然而,Gemini 2.5 Pro的辉煌成就远不止于此。它不仅在大模型竞技场这一衡量人类偏好的平台上独占鳌头,还在编程、数学及科学基准测试中占据领先地位,尤其是在被誉为“人类最后考试”的超高难度测试中,相较于OpenAI o3-mini,其得分提升了近5%,提升幅度高达34%。更令人兴奋的是,该模型现已支持100万tokens的上下文窗口,并计划不久的将来扩展至200万tokens。
目前,开发者们已能在谷歌AI Studio平台上体验到Gemini 2.5 Pro的魅力,而普通用户则需拥有Gemini Advanced订阅账号方能一探究竟。据悉,谷歌将在未来几周内公布该模型的定价策略,届时用户将有机会利用这一高性能模型进行大规模商用。
为了直观展示Gemini 2.5 Pro的强大功能,谷歌DeepMind在其YouTube频道上发布了一系列演示视频,生动呈现了其编程能力与其他领域的深度融合。例如,该模型能够根据用户指令,在p5.js中探索曼德博集合,生成边缘清晰、色彩过渡平滑的可视化效果。它还能根据提示词创建互动式图表,将人均GDP与健康数据巧妙结合,揭示两者之间的微妙关系。
在编程领域,Gemini 2.5 Pro同样展现出了非凡实力。无论是创建美观的Web应用,还是在智能体编程、代码转换与编辑任务中,它都表现出色。尽管在SWE-bench verified基准测试中,其得分低于Claude 3.7 Sonnet,但采用定制智能体配置仍取得了63.8%的亮眼成绩。
作为Gemini模型家族的一员,Gemini 2.5 Pro继承了原生多模态处理能力和超长上下文窗口的优势。目前,它能够处理高达100万tokens的上下文信息,并即将升级至200万tokens,这意味着它将能够解析更为复杂的数据集,处理来自文本、音频、图像、视频乃至完整代码库等多元信息源的挑战。
Gemini 2.5 Pro的发布与DeepSeek-V3新版本的问世几乎同时发生,两者都不约而同地提升了在编程、审美、数学等方面的能力,并将其作为核心亮点进行展示。这一趋势表明,AI编程能力的提升已成为大模型厂商竞相追逐的新前线,不仅将为用户带来更为直观的使用体验变化,更有望在生产场景中实现显著的效益提升。