阿里云在最新一轮的技术创新中,推出了通义千问Qwen模型家族的新成员——Qwen2.5-Omni。这款旗舰级端到端多模态模型不仅向公众展示了其强大的技术实力,还通过开源的方式,在Hugging Face、ModelScope、DashScope和GitHub等平台上供开发者使用。
Qwen2.5-Omni专为全面的多模态感知设计,能够无缝处理包括文本、图像、音频和视频在内的多种输入形式。其独特之处在于,能够实时以流式方式响应,并同时生成文本和自然语音合成的输出。这一特性使得Qwen2.5-Omni在交互体验上达到了新的高度。
Qwen团队此次引入了全新的Thinker-Talker架构,这一架构是Qwen2.5-Omni的核心创新之一。Thinker模块如同大脑,负责处理多模态输入,生成高层语义表征和对应文本内容;而Talker模块则像发声器官,接收Thinker实时输出的语义表征和文本,以流式方式流畅合成离散语音单元。这种架构不仅提高了模型的处理效率,还保证了输出的自然性和稳定性。
在实时音视频交互方面,Qwen2.5-Omni同样表现出色。其架构支持完全实时交互,能够分块输入并即时输出,为用户提供了流畅无阻的交互体验。Qwen2.5-Omni在语音生成的自然性和稳定性方面也超越了现有的许多流式和非流式替代方案。
在性能表现上,Qwen2.5-Omni同样不容小觑。与同等规模的单模态模型相比,Qwen2.5-Omni在多模态任务中展现出了卓越的性能。在音频能力上,它优于类似大小的Qwen2-Audio,并与Qwen2.5-VL-7B保持同等水平。同时,Qwen2.5-Omni在端到端语音指令跟随方面也表现出色,与文本输入处理的效果相媲美。

模型架构图
为了更直观地展示Qwen2.5-Omni的性能优势,阿里云还提供了多个基准测试的结果。在多模态任务OmniBench中,Qwen2.5-Omni达到了SOTA(State-of-the-Art)的表现。在单模态任务中,Qwen2.5-Omni也在多个领域中表现优异,包括语音识别、翻译、音频理解、图像推理、视频理解以及语音生成等。
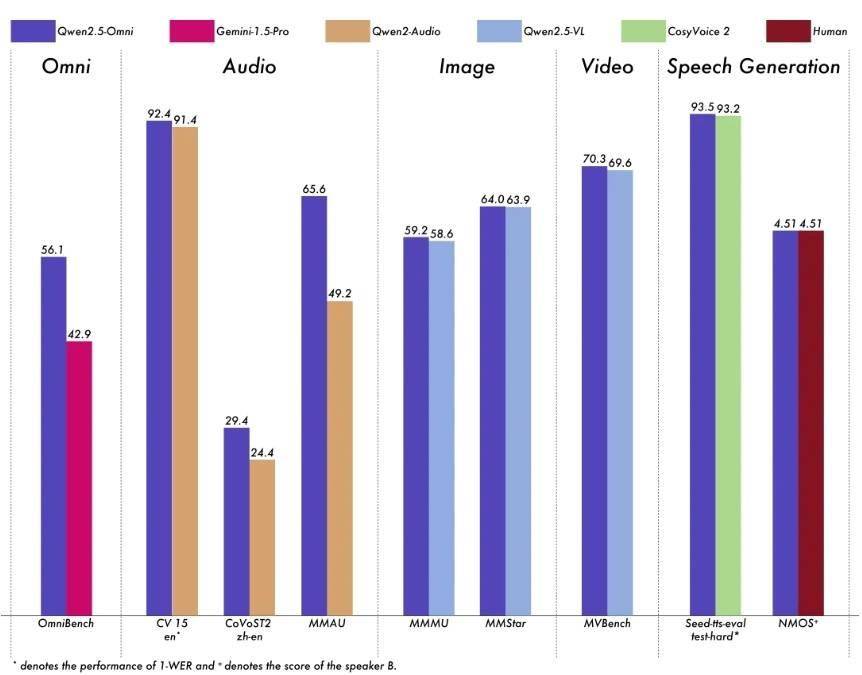
模型性能图
对于开发者而言,Qwen2.5-Omni的开源无疑是一个巨大的福音。他们可以通过访问Hugging Face、ModelScope、DashScope和GitHub等平台,轻松获取模型并进行二次开发。这不仅有助于推动人工智能技术的进一步发展,还为开发者提供了更多的创新机会。
如果你对Qwen2.5-Omni感兴趣,不妨亲自体验一下。你可以通过访问ModelScope平台上的Qwen2.5-Omni Demo页面,感受这款旗舰级多模态模型的强大魅力。