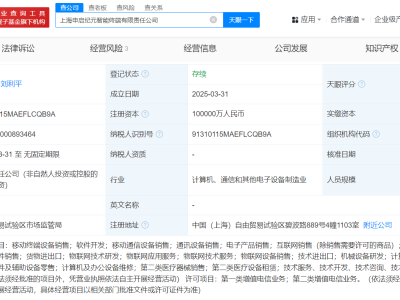
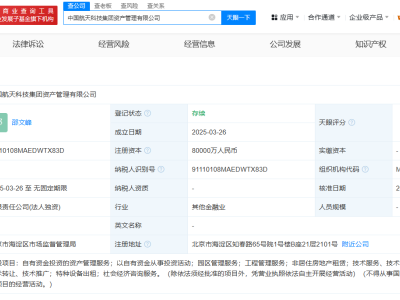
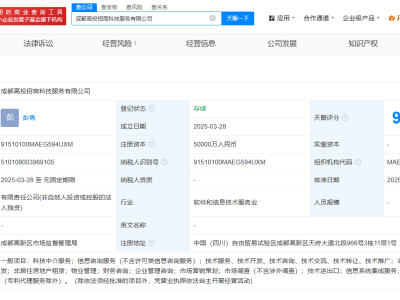
近期,科技界迎来了一项创新突破,数据智能领域的佼佼者Databricks推出了一种名为TAO(测试时自适应优化)的新型大语言模型微调技术。这项技术通过整合无标注数据和强化学习,不仅大幅削减了企业成本,还显著提升了模型性能。
据悉,TAO方法的核心在于其独特的测试时计算能力,能够自动探索任务的各种可能性,并结合强化学习技术对模型进行优化。这一过程省去了繁琐的人工标注,使得企业在应用大语言模型时更加高效和经济。
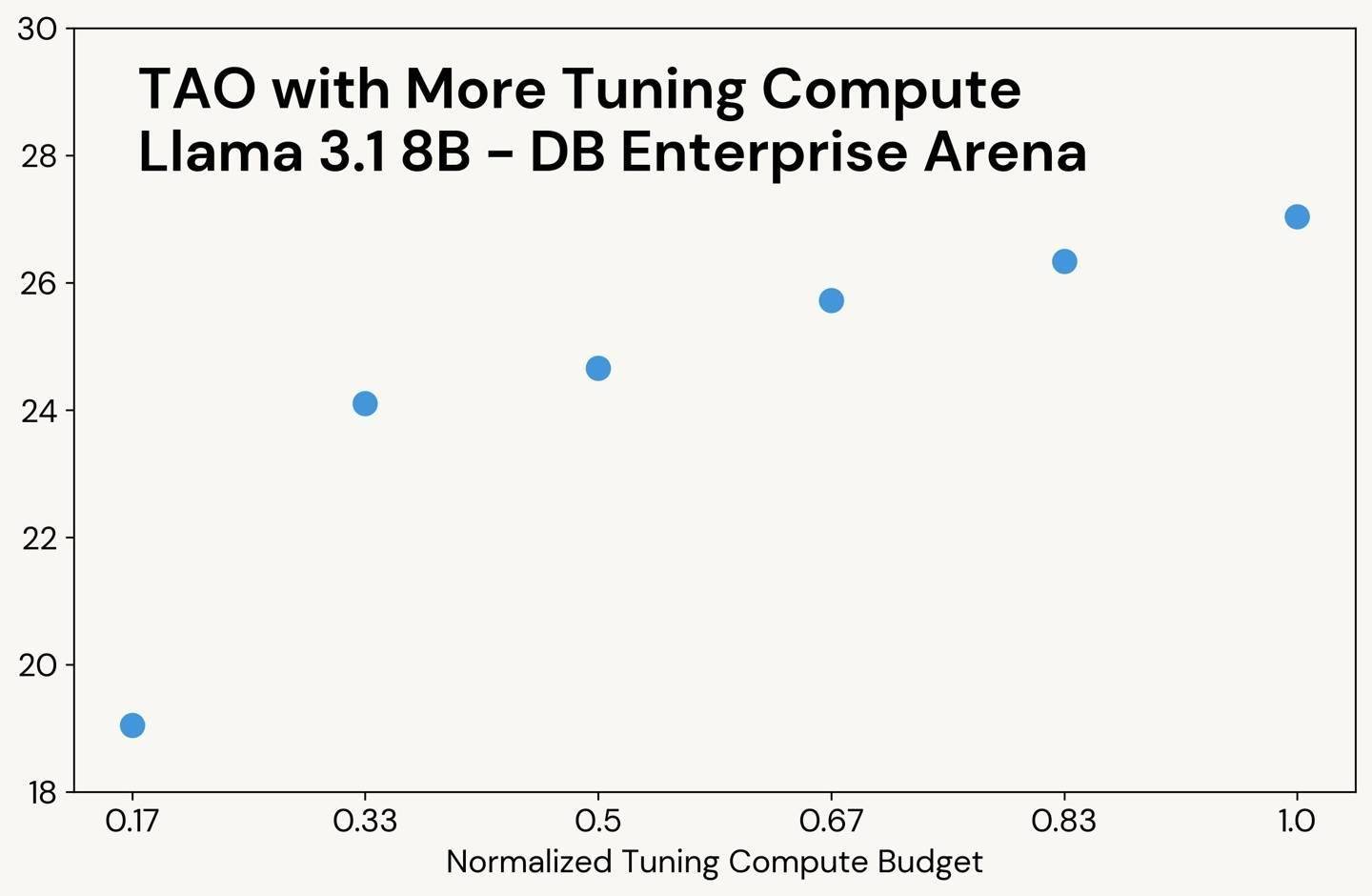
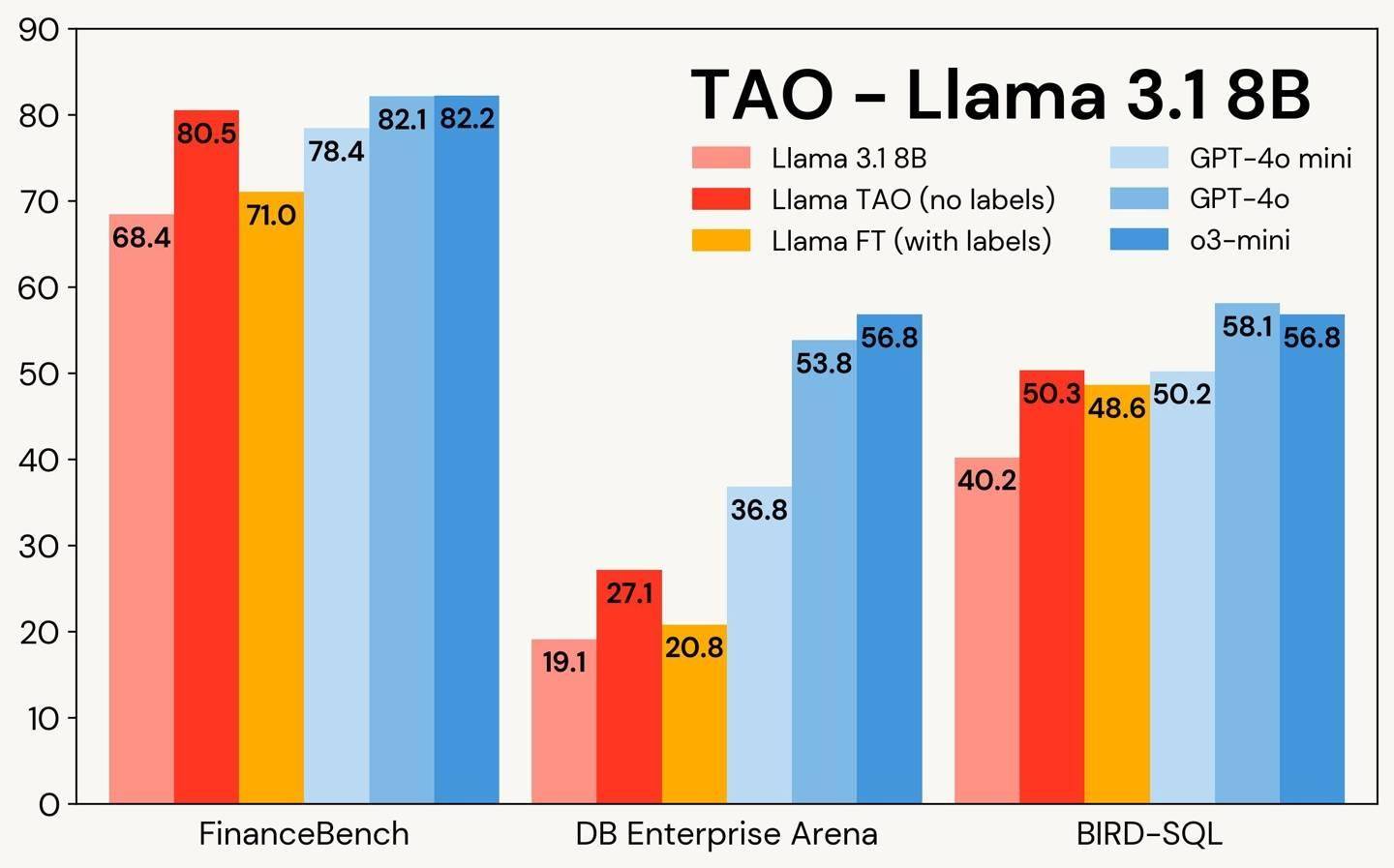
在实际测试中,TAO技术展现出了惊人的实力。以金融文档问答和SQL生成任务为例,经过TAO微调的Llama 3.3 70B模型,其表现甚至超越了传统的标注微调方法,直逼OpenAI的顶级闭源模型。这一成果无疑为行业树立了新的标杆。
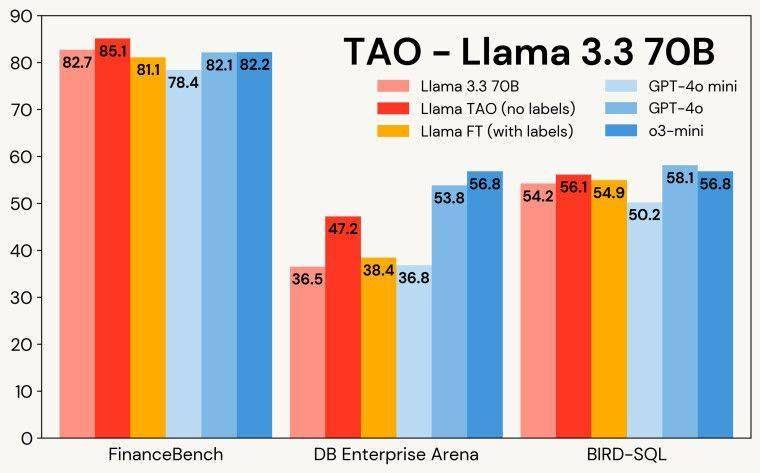
具体来看,在FinanceBench基准测试中,包含7200道SEC文档问答的任务中,TAO模型以85.1的高分领先,优于标注微调(81.1分)和OpenAI的o3-mini模型(82.2分)。在BIRD-SQL测试中,TAO模型同样表现出色,以56.1分接近GPT-4o的58.1分,并远超标注微调方法的54.9分。尽管在DB Enterprise Arena测试中,TAO模型以47.2分略低于GPT-4o的53.8分,但其整体表现依然令人瞩目。
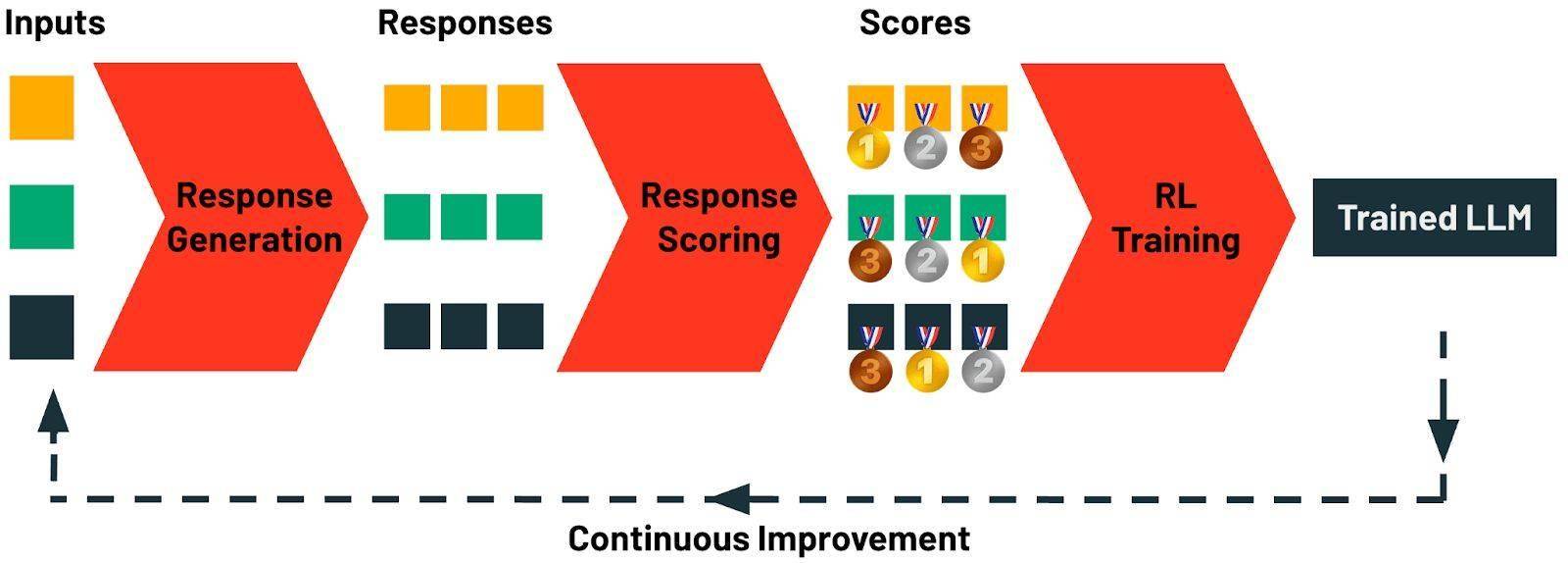
TAO技术的推出,不仅为开源模型提供了一条持续进化的路径,还赋予了模型通过用户反馈数据自我优化的潜力。随着用户使用的增多,模型将不断学习和改进,进一步提升其性能和适用性。
目前,TAO技术已在Llama模型上启动了私密测试。企业用户可以通过申请表单参与测试,率先体验这一创新技术带来的变革。随着测试的深入和技术的不断成熟,TAO有望在未来成为推动大语言模型应用发展的重要力量。