近日,海外知名大模型产品平台OpenPipe公布了一项令人瞩目的研究成果,该研究成功地在重度推理游戏《时空谜题》中,利用一种名为GRPO的强化学习算法,使小型开源模型的表现超越了多个业界领先的推理模型,包括DeepSeek R1、OpenAI的o1和o3-mini,以及Anthropic的Claude Sonnet 3.7。
这项研究的作者是来自Ender Research的强化学习专家Brad Hilton和OpenPipe的创始人Kyle Corbitt。他们的研究表明,通过精心设计的训练策略,不仅显著缩小了与Claude Sonnet 3.7在推理能力上的差距,还实现了超过百倍的成本优化。
报告详细阐述了任务设计与超参数调整的过程,并分享了基于torchtune框架构建的完整训练方案,为业界提供了宝贵的参考。
自OpenAI去年发布o系列推理模型以来,大型语言模型(LLMs)在强化学习(RL)训练下迎来了飞速发展。然而,尽管取得了显著进展,逻辑演绎能力仍是顶尖模型的短板。当前LLMs普遍难以稳定追踪细节、保持逻辑严密以及实现多步衔接的可靠性。即便是顶尖模型,在生成长输出时也常出现低级错误。
面对这一挑战,研究团队决定从小型开源模型入手,探索其在全新推理任务上的潜力。他们选择了《时空谜题》作为实验平台,这是一款灵感源自经典桌游Clue的单人逻辑谜题,不仅包含了标准的推理要素,还增加了时间和动机两个维度,使得谜题更加复杂且富有挑战性。
在基准测试中,Claude Sonnet 3.7在设定6.4万个token的情况下表现最佳,而DeepSeek R1与OpenAI的o1和o3-mini表现相近。相比之下,未经调优的小型开源模型Qwen则显得逊色。然而,研究团队相信,只要方法得当,这些小型模型同样能达到前沿水平。
为了训练出具有前沿推理能力的模型,研究团队采用了强化学习方法,并选用了DeepSeek模型的GRPO算法。他们让大语言模型针对每个谜题生成多个回复,并通过正向强化和惩罚机制来引导模型学习正确的推理过程。在训练过程中,他们还使用了vLLM推理引擎、HuggingFace Transformers AutoTokenizer等工具来处理回复和数据打包。
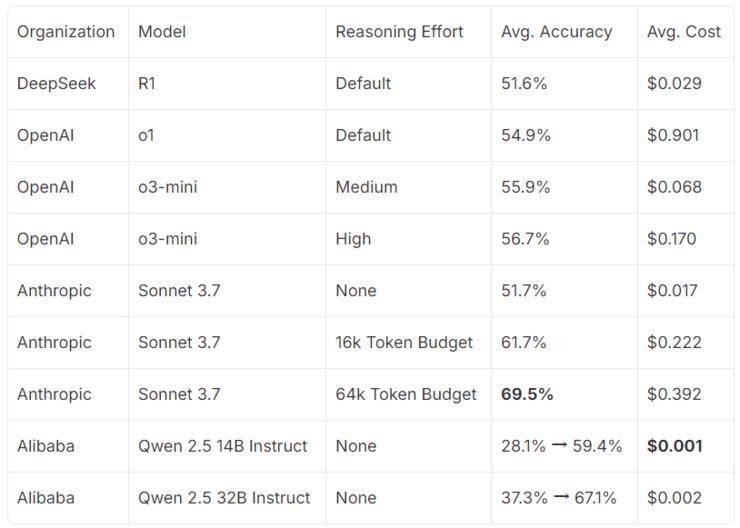
经过上百次的迭代训练,研究团队成功地将Qwen模型提升到了前沿推理水平。在最佳状态下,140亿参数的Qwen模型在1.6万个token的设置下已接近Claude Sonnet 3.7的性能,而320亿参数的模型则几乎达到了Sonnet的结果。研究还发现,在训练过程中,输出长度呈现出有趣的规律,这可能与模型的推理能力提升有关。
为了从定性角度评估逻辑推理能力的提升,研究团队还让Claude Sonnet 3.7对训练后的Qwen 32B模型的推论进行识别。结果显示,Sonnet从基础模型中识别出的推论大多被判定为错误,而从训练后的模型中识别出的推论则大多被判定为逻辑合理。
最后,研究团队还估算了Qwen模型的成本效益。他们发现,在假设按需部署具有足够吞吐量的情况下,训练后的模型在准确性和推理成本之间实现了显著的权衡优化。
这项研究不仅展示了强化学习在训练小型开源模型处理复杂演绎任务方面的巨大潜力,还为业界提供了宝贵的经验和参考。未来,随着技术的不断发展,我们有理由相信,更多的小型模型将能够通过强化学习实现前沿水平的推理能力。