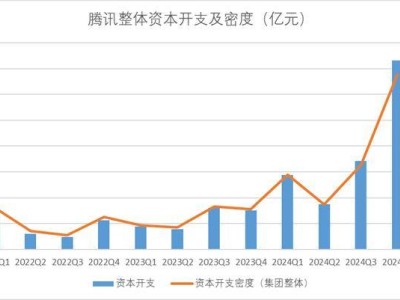
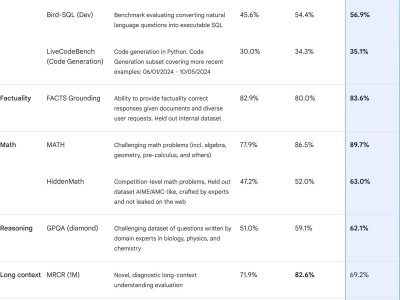
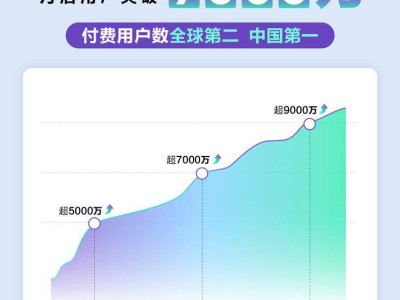
在人工智能领域,一场关于大模型的激烈竞赛正在悄然上演。近日,阿里巴巴和字节跳动不约而同地宣布了自家大模型的重大升级,标志着这场竞赛进入了新的阶段。
3月28日,阿里推出了全新的视觉推理模型QVQ-Max,该模型不仅具备看图、读视频的能力,还能解决复杂的数学问题。而字节方面,其豆包模型也迎来了新版“深度思考”功能的测试,该功能允许模型在推理过程中动态发起搜索,实现“边想边搜”的智能化体验。
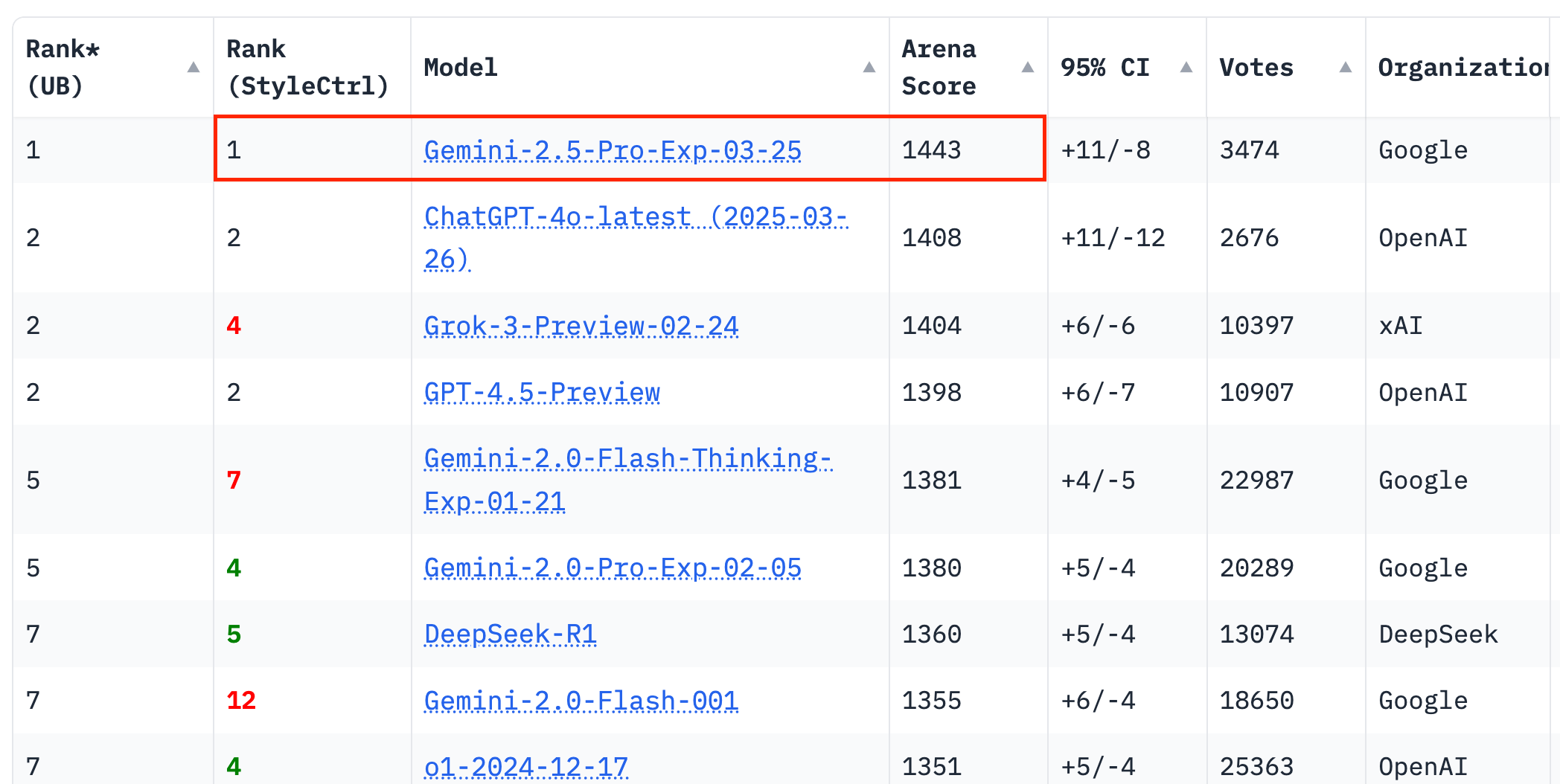
事实上,这两家公司的升级并非孤立事件。近期,多家主流大模型都发布了新版本。DeepSeek推出了V3-0324版本,在推理、写作、编码能力上均有提升;Google则推出了Gemini-2.5-Pro,该模型在LMArena榜单上取得了40分的优异成绩,领先其他模型;OpenAI也不甘落后,其GPT-4o的图像生成功能得到了显著增强。
这一系列更新,无疑让大模型领域的竞争变得更加激烈。从图像生成到视觉推理,从多模态到超长上下文,各大模型都在全方位提升自己的能力。这场竞赛,已经不仅仅局限于功能的比拼,更是质量、智能体时代基础模型提供能力的全方位较量。
阿里的QVQ-Max,以其强大的视觉推理能力脱颖而出。该模型能够“看懂”图表、照片,甚至对视频内容进行理解,结合这些信息进行分析、推理,给出解决方案。无论是复杂的几何图形还是日常生活中的照片,QVQ-Max都能快速识别出关键元素,并进一步分析这些信息,结合背景知识得出结论。
而字节的豆包新版“深度思考”功能,则主打推理进阶。该功能支持模型在思维链条展开的同时动态发起搜索,实现“边想边搜”。在实际应用中,豆包会在思考过程中搜索资料,不断通过搜索补充信息再思考,从而更准确地回答用户的问题。
DeepSeek的V3-0324版本,虽然只是小版本升级,但每一点都变得更加强大。该版本借鉴了DeepSeek-R1在模型训练中使用的强化学习技术,针对推理、写作、编程能力做了进一步优化。新版模型在前端开发能力上更为出色,能生成更具现代设计感的网页结构;写作方面则明显提升了中文中长篇文本的逻辑性和通顺度。
Google的Gemini 2.5 Pro,则是此次升级中的一大亮点。作为Google首个“全能型智能体底座”模型,Gemini 2.5 Pro在对话能力上技压群雄,同时在编码、数学、视觉推理、搜索调度等能力上都得到了全面增强。该模型正在将“大语言模型”推向“高可信度、多轮决策型智能体”的方向演进。
最后,不得不提的是OpenAI的GPT-4o。此次升级中,GPT-4o的原生图像生成功能无疑是最吸引眼球的。无数网友在尝试新版本的图像生成功能后,纷纷表示效果震撼。GPT-4o不仅提高了对复杂指令的理解能力,还显著提升了图文混排渲染的可控性。尤其是在生成图像中的文字内容上,准确率大幅提升。新版GPT-4o还支持多轮对话过程中连续地修改图像风格与构图元素,逐步调优,视觉一致性更强。

随着各大模型的不断升级,智能体时代已经逼近。大模型们正在全方位补齐能力,为智能体的爆发做准备。推理能力、内容生成质量、系统调度能力……这些基础能力的全方位提升,正在让这场竞赛变得越来越激烈。而在这场竞赛中,谁能够脱颖而出,成为智能体时代的领航者,让我们拭目以待。