在科技界万众瞩目的期待中,OpenAI似乎即将迈出重大的一步,兑现其一个多月前关于推出开源模型的暗示。4月1日,OpenAI的首席执行官山姆·奥特曼(Sam Altman)在社交平台X上(原Twitter)发布了一条引人注目的消息:OpenAI计划在未来数月内,发布一款功能强大且具备推理能力的“开放权重”(Open-Weight)大型模型。
这一消息迅速引发了全球科技媒体的广泛关注和报道,许多中文媒体以“OpenAI即将发布开源模型”为标题进行了跟进。不少行业观察者将这一举措视为OpenAI“重新拥抱开源”的重要标志。
然而,值得注意的是,山姆·奥特曼在公告中并未直接使用“开源”(open-source)一词,而是选择了更为谨慎的表述——“开放权重”(open-weight)。这一表述引发了网友们的广泛讨论和争议。所谓“开放权重”,指的是模型训练完成后,其参数将对外开放,开发者可以基于这些权重进行部署、测试和微调。但这并不包括训练数据、完整训练代码,也不保证无门槛使用。
与许多人认知中的“开源”——即代码、数据、方法全面透明、自由使用——相比,“开放权重”显然存在一定的差距。它更像是一种妥协,旨在保留核心技术壁垒的同时,向开发者社区释放部分能力。这种做法可以降低模型的使用门槛,但难以满足真正的可验证性和可重现性需求。
事实上,OpenAI新模型的“开放权重”做法并非孤例。DeepSeek、阿里Qwen和meta的LLaMA等模型,在开源策略上虽然各有侧重,但核心共同点都是开放权重,允许外部开发者直接部署,并提供推理代码、微调脚本和评估工具等。这意味着开发者可以直接下载模型进行本地部署、微调和推理服务,这可以说是大模型“开源”的最低门槛。

不过,尽管都是开放权重,但实际的开放程度却各不相同。以DeepSeek为例,它发布的V2、V3、R1等模型均开放了权重,还有相应的技术报告,并采用了限制极少的MIT开源协议。阿里的Qwen模型则采用了同样比较宽松的Apache 2.0开源协议,允许用户自由地使用、修改和分发代码,包括商业用途。相比之下,meta的LLaMA虽然也开放了模型参数和推理脚本,但其使用协议限制更多,导致其在开源社区的热度虽高,但落地场景有所受限。

从某种程度上说,OpenAI即将发布的新模型,虽然尚未公布具体的开源策略,但如果也开放模型权重和推理代码,支持开发者本地部署,那么从行业实践标准来看,它完全可以被归入今天“开源模型”的范畴之中。这一举措无疑将对开源模型社区产生深远影响。
回顾历史,OpenAI在GPT-2时期就有了“闭源路线”的打算,尽管当时因舆论压力而公开了满血版GPT-2,但从GPT-3开始,OpenAI彻底走上了闭源路线。因此,这一次“重新开放”也可以视为OpenAI对社区释放出的一个积极信号。
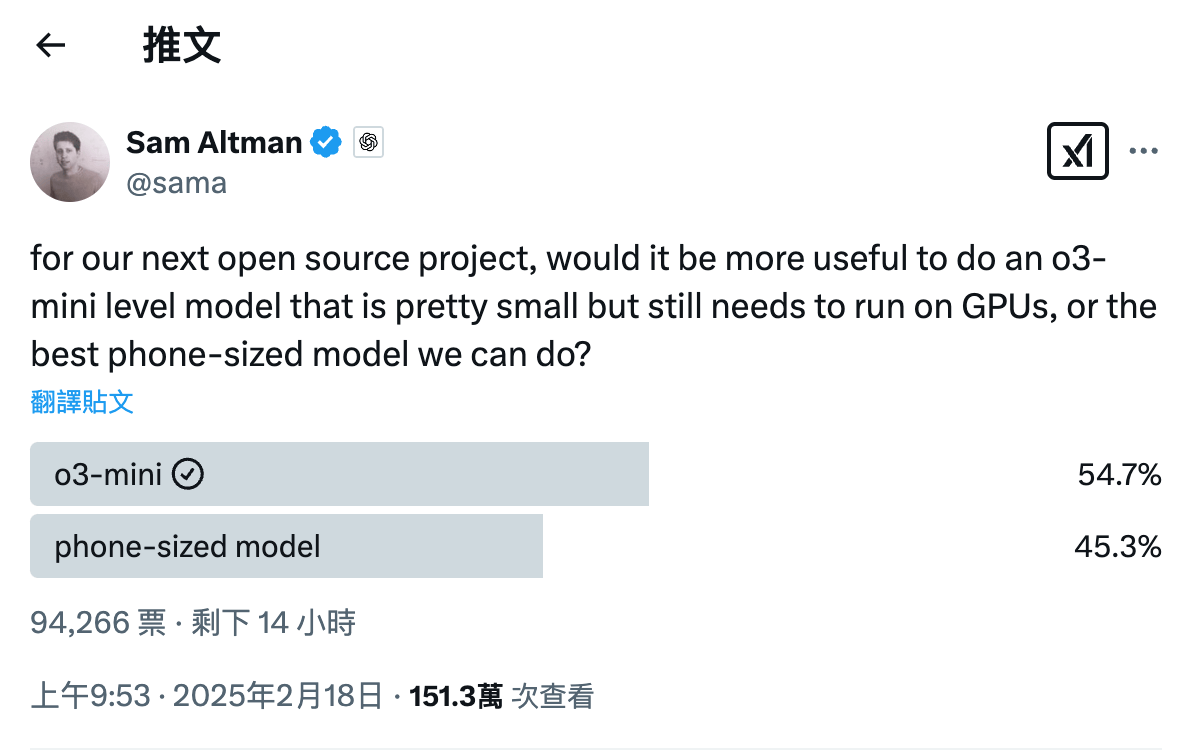
山姆·奥特曼在今年2月就曾暗示过OpenAI开源模型的方向将是“o3-mini级别”与“手机端侧级别”其中之一。结合最新推文中提到的“具备推理能力的强大新开放权重模型”,基本可以推断出OpenAI在开源路线上最终选择了一个“o3-mini级别”的模型来打开局面。这一选择无疑更具战略意义,因为推理能力已经成为大模型发展的共识和外界关注的重点。
随着开源模型生态的迅速繁荣,meta、Mistral、Qwen、DeepSeek等模型纷纷涌现,一边打造模型,一边构建生态。越来越多硬件和软件厂商加入开源模型生态之中,放弃自主训练大模型的路径,专注于模型微调和应用落地。对于OpenAI来说,这无疑构成了一种潜在的威胁。因此,OpenAI此次重返开源社区,不仅是为了发布一个模型,更是为了巩固其在行业中的地位,并可能改变整个开源模型社区的格局。