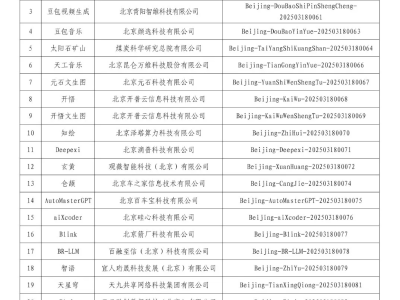
亚马逊公司近期宣布了一项重大进展,正式推出了其最新的生成式AI语音模型——Nova Sonic。这一创新标志着亚马逊在人工智能语音技术上的重大飞跃。
Nova Sonic具备卓越的能力,可以无缝处理语音输入,并生成极其自然流畅的语音输出。在速度、语音识别精确度和对话质量等关键性能指标上,它已与OpenAI、谷歌等行业领先者的尖端语音模型并驾齐驱。这一成就展现了亚马逊在AI语音技术领域的深厚积累和持续创新。
通过亚马逊Bedrock开发者平台,Nova Sonic提供了强大的支持,特别是其创新的双向流式API接口,为企业级AI应用开发开辟了新天地。尤为该模型在成本效益上具有显著优势,价格相较于OpenAI的GPT-4o降低了约80%,成为了当前市场上性价比极高的AI语音解决方案。
相较于其他竞争对手的AI语音模型,Nova Sonic在路由用户请求至不同API方面的表现尤为出色。它能够智能地判断何时需要从互联网获取实时信息、解析专有数据源,或在外部应用程序中采取行动,并选用最合适的工具来完成这些任务。这种灵活性使其在实际应用中更具竞争力。
在双向对话场景中,Nova Sonic展现了其高度的智能性。它能够等待合适的时机发言,充分考虑到说话者的停顿和打断等情况,使对话更加自然流畅。Nova Sonic还能够为用户的语音生成文本记录,这些文本记录可被开发者广泛应用于各种场景,进一步拓宽了其应用范围。

据亚马逊AGI部门首席科学家罗希特·普拉萨德透露,Nova Sonic的部分技术已经应用于升级版的数字助手Alexa+。这一举措不仅提升了Alexa+的功能和性能,也彰显了亚马逊在构建人工通用智能(AGI)战略上的坚定步伐。未来,亚马逊还将推出支持多模态理解的AI模型,涵盖图像、视频及其他物理世界的感知数据,进一步推动AI技术的发展和应用。