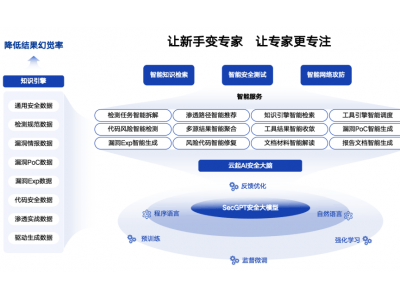
在AI技术日新月异的今天,一款名为可灵AI的平台再次引领了行业潮流。近日,可灵AI正式推出了其2.0版本的视频与图像生成模型,标志着AI内容创作领域的一次重大飞跃。
据悉,可灵2.0视频生成模型在文生视频和图生视频两大领域均取得了显著成就。与OpenAI的Sora相比,可灵2.0在文生视频领域的胜负比高达367%;而与谷歌的Veo2相比,在图生视频领域的胜负比也达到了182%。这一数据无疑彰显了可灵AI在视频生成技术上的领先地位。
与前一版本相比,可灵2.0在多个维度上实现了显著提升。在动态质量方面,它更加流畅自然,能够准确捕捉并呈现复杂动作和表情的变化。在语义响应方面,它更准确地理解了用户的意图,生成的内容更加贴合用户的描述。在画面美学方面,可灵2.0也展现出了更高的水准,色彩搭配、光影效果以及整体构图都更加出色。
与此同时,可灵AI还推出了全新的图像生成模型——可图2.0。该模型在指令遵循、电影质感及艺术风格表现等方面均有所提升。色彩更加鲜明,光影效果更加立体,情绪表达也更具感染力。可图2.0还新增了60余种风格化效果,为用户提供了更多样化的创作选择。
除了技术和模型上的升级,可灵AI还带来了全新的交互理念——Multi-modal Visual Language(MVL)。这一理念允许用户利用图像参考、视频片段等多模态信息,将复杂的创意直接高效地传达给AI。用户可以将视频、图片等元素上传,并将其嵌入至提示词中,这些元素会在画面内以合乎逻辑的方式组合,进一步提升画面的可控性。
自发布以来,可灵AI已迅速积累了庞大的用户群体。截至目前,其全球用户规模已突破2200万,月活用户量在过去10个月内增长了25倍。用户们利用可灵AI生成了超过1.68亿个视频和3.44亿张图片,充分展示了该平台的创作潜力和用户黏性。
可灵AI的成功离不开其背后团队的不断努力和创新。他们采用了全新的DiT和VAE架构,提升了模型的信息融合能力和画面过渡效果。同时,他们还利用强化学习技术优化了模型的推理策略,使其能够更好地理解和响应复杂运动场景和主体交互。这些技术创新共同推动了可灵AI的不断发展。