近期,科技领域迎来了一波新的模型发布高潮,其中OpenAI推出的GPT-4.1系列模型尤为引人注目。据bleepingcomputer报道,这一最新版本相较于其前身GPT-4o,在性能上实现了显著飞跃。
OpenAI于4月15日正式揭晓了GPT-4.1、GPT-4.1 mini及GPT-4.1 nano三款新模型。从官方公布的跑分数据来看,这些新模型在编程能力上有了质的飞跃,远远超越了GPT-4o及其小型版本GPT-4o mini。以SWE-bench Verified跑分为例,GPT-4o仅获得了21.4%的分数,而GPT-4.1则一举跃升至54.6%,展现出了强大的编程实力。
然而,尽管GPT-4.1系列模型在性能上取得了显著提升,但在与谷歌Gemini系列的对比中,却并未能占据上风。根据Stagehand发布的基准数据,Gemini 2.0 Flash在错误率和精确匹配率上均表现优异,错误率仅为6.67%,精确匹配率高达90%,且价格更为亲民,速度更快。相比之下,GPT-4.1的错误率则高达16.67%,成本更是Gemini 2.0 Flash的十倍以上。
来自哈佛大学的RNA科学家Pierre Bongrand也提供了相关数据,进一步印证了GPT-4.1在性价比方面的不足。他指出,相较于Gemini 2.0 Flash、Gemini 2.5 Pro及DeepSeek等竞品,GPT-4.1的性价比并不具备优势。

在编码专项测试中,GPT-4.1的表现同样未能让人眼前一亮。Aider Polyglot的测试结果显示,GPT-4.1的编码得分仅为52%,而谷歌的Gemini 2.5则以73%的得分遥遥领先,进一步凸显了GPT-4.1在编码能力上的不足。
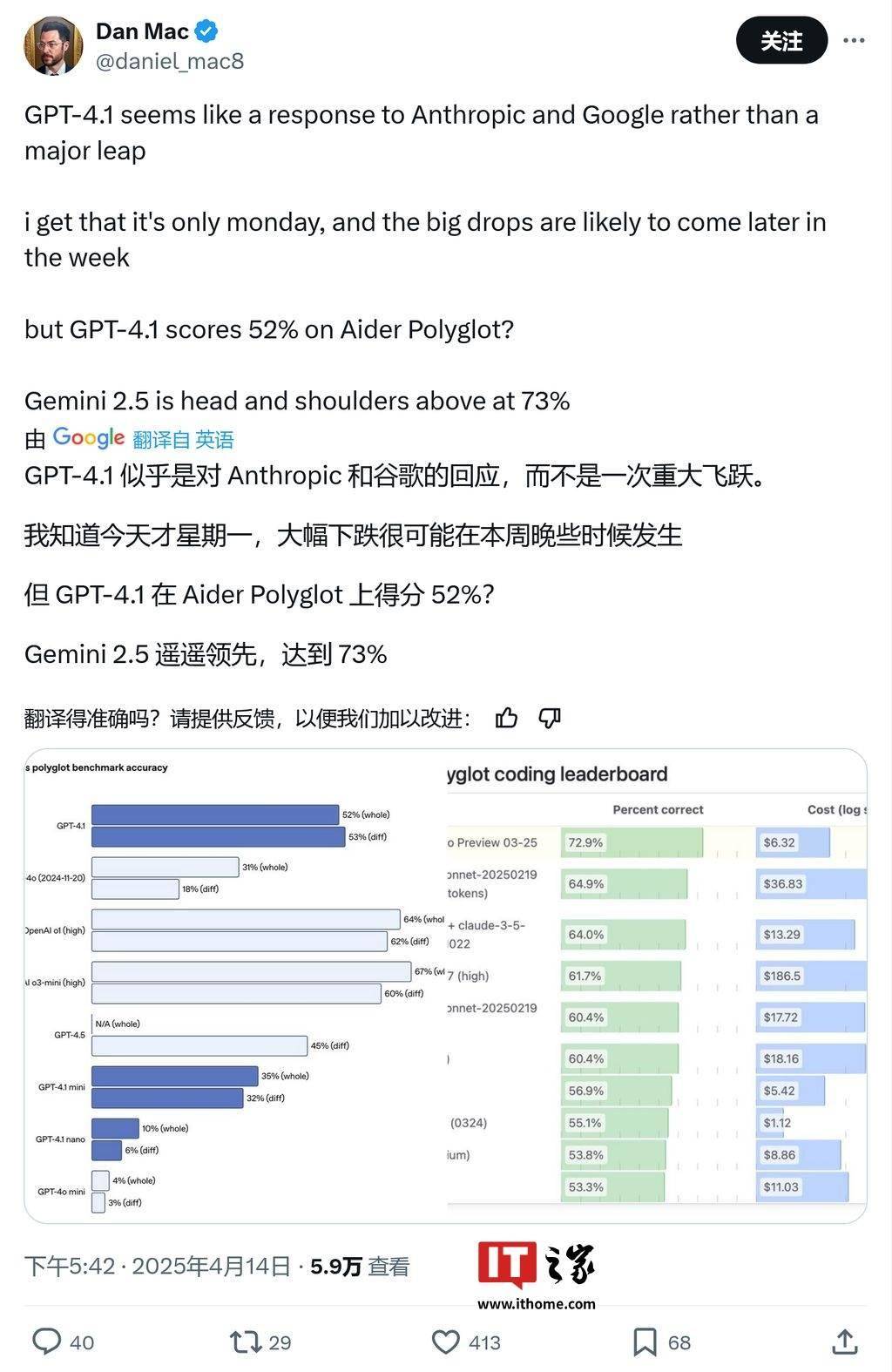
值得注意的是,尽管GPT-4.1被归类为非推理模型,但其在编码能力方面依然处于行业领先地位。这一成绩无疑为OpenAI的AI研发实力提供了有力证明,同时也为未来的AI模型发展提供了更多可能性。
然而,在与谷歌Gemini系列的对比中,GPT-4.1也暴露出了自身在性价比和错误率方面的不足。这提醒我们,在AI技术的快速发展中,仍需不断追求性能与成本的平衡,以更好地满足实际应用需求。