在春意盎然的四月初,2025中国生成式AI大会(北京站)以“大拐点 新征程”为主题,成功吸引了50余位产学研领域的杰出嘉宾以及1500名热情观众。这场盛会不仅是思想碰撞的舞台,更是技术创新的前沿阵地。
GMI Cloud亚太区总裁King Cui在会上发表了一场引人入胜的演讲,题目为《AI推理的全球算力革命:从单点爆发到全球扩容》。他深入阐述了GMI Cloud如何通过构建顶级生态合作,获取高端硬件资源,并利用自研的Cluster Engine云平台和Inference Engine推理引擎云平台,实现算力的全球化智能调度、扩容及性能最大化。
King Cui强调,在AI推理时代,GMI Cloud致力于重构AI算力的成本效益模型,为AI应用的研发提供灵活、全球化的算力底座。这不仅能够帮助企业在全球市场中凭借算力优势构建商业壁垒,更能推动“全球AGI”从技术愿景走向商业现实。

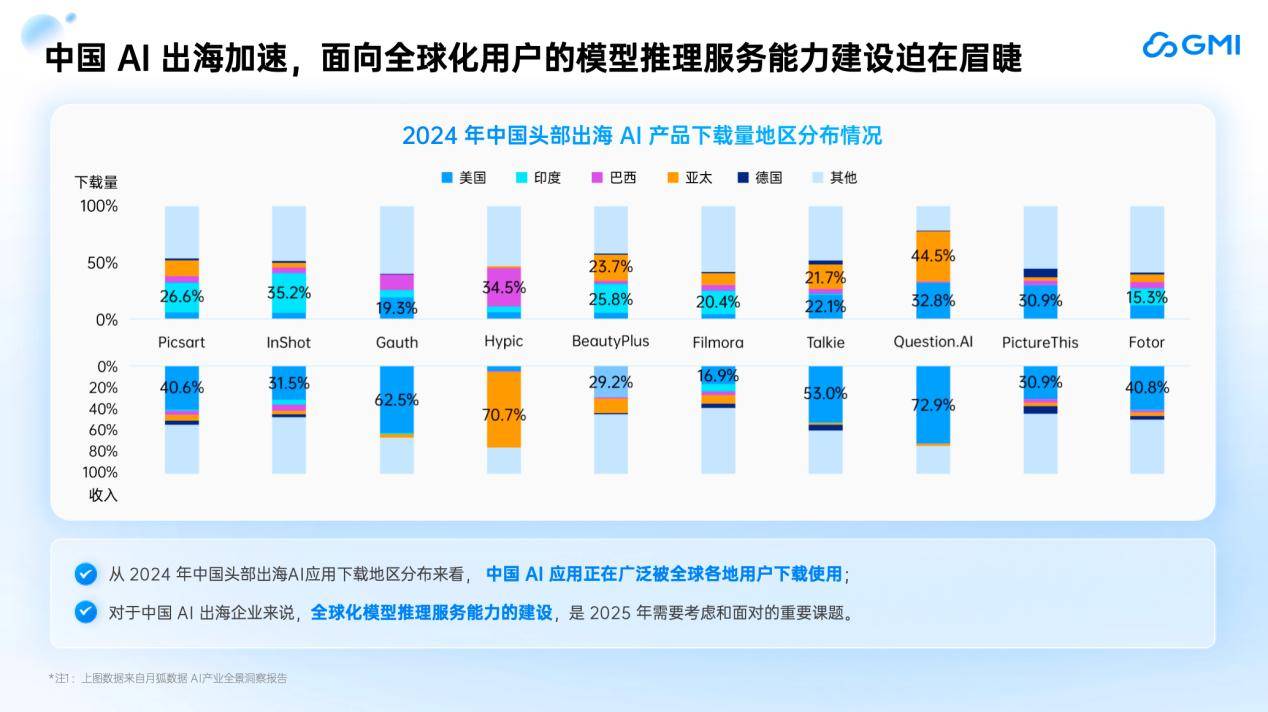
演讲中,King分享了一个引人深思的数据:中国AI应用的下载量年增速已超过100%,但算力稳定性与成本效率仍是制约其发展的核心瓶颈。在全球AI应用爆发式增长的背景下,算力已成为驱动技术落地与商业扩张的关键生产要素。
作为NVIDIA全球TOP 10的NCP,GMI Cloud已在北美、欧洲、亚太等地部署了12座数据中心,助力企业实现全球算力调度与扩容。GMI Cloud凭借其“技术纵深+全球布局”的双轮驱动战略,构建了涵盖硬件适配、弹性调度、性能优化与稳定保障的全栈解决方案,有效破解了企业出海面临的算力部署难题。
King Cui的演讲实录精华进一步揭示了GMI Cloud的核心竞争力。他介绍道,GMI Cloud是一家专注于为全球化AI应用提供英伟达最新GPU云服务的AI Native Cloud公司。作为NVIDIA的紧密合作伙伴,GMI Cloud不仅定期与NVIDIA进行技术交流,还凭借投资者的支持,在亚太地区拥有最新的GPU分配权,能够快速获取并部署最先进、最强大的GPU云服务。
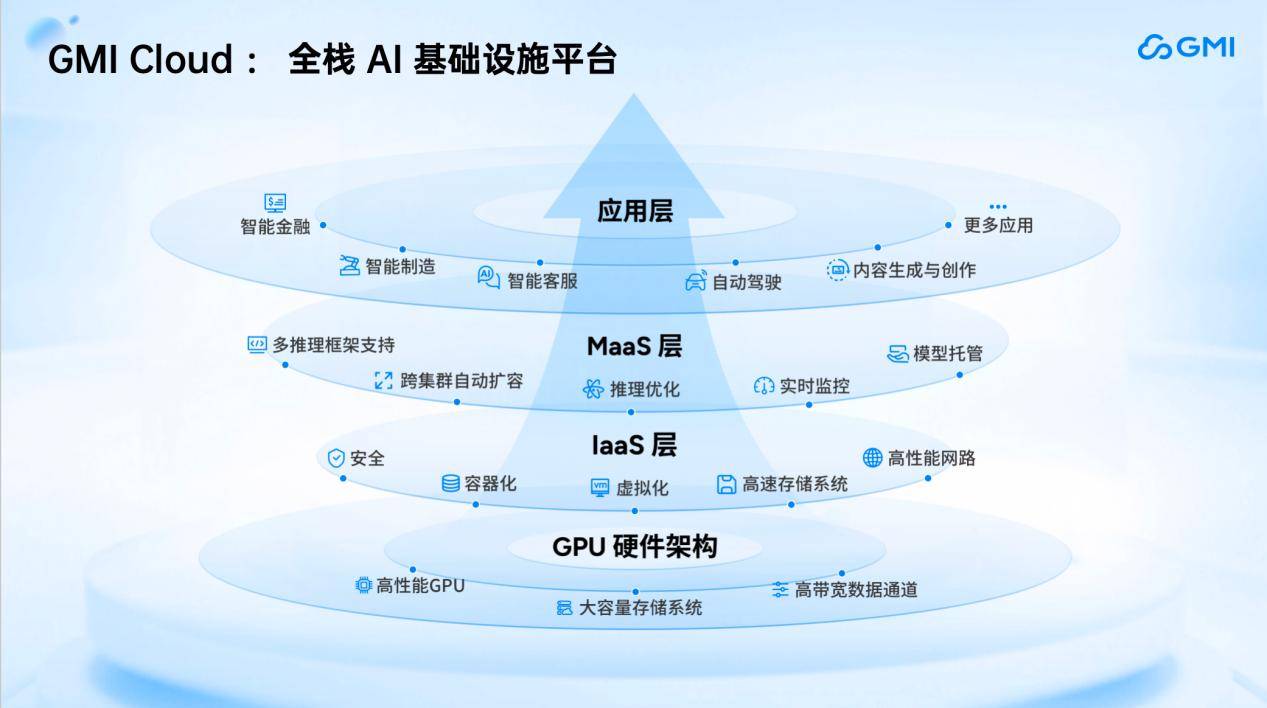
从技术架构上看,GMI Cloud提供了从底层GPU硬件到支持应用层的全栈服务。底层提供NVIDIA生态体系内最新、最强的GPU云资源及AI存储云服务,支持NVMe高速存储和普通存储,适配不同场景。网络层面则提供高速带宽数据通道,确保AI应用的高效运行。GMI Cloud还集成了大量开源大模型,并基于自研的Inference Engine推理引擎平台,实现了对英伟达H100、H200及更先进B200的适配,提升了模型的token吞吐速度。
King Cui还指出,随着AI应用的全球化趋势日益明显,推理服务的及时性、扩展性和稳定性已成为提高用户留存的核心挑战。他通过分享Manus和Deepseek等成功案例,生动诠释了后端推理云服务算力在应对大规模用户涌入时的重要性。
为了应对这些挑战,GMI Cloud推出了Inference Engine推理服务。该服务部署在自研的Cluster Engine云管平台上,能够实现全球范围内的GPU云服务就近调度。Inference Engine具备四大核心能力:弹性伸缩与跨集群自动扩容、可视化部署工作流、集成最先进高性能GPU以及主动监控与故障恢复。这些能力共同构成了GMI Cloud破解AI应用全球化难题的利器。
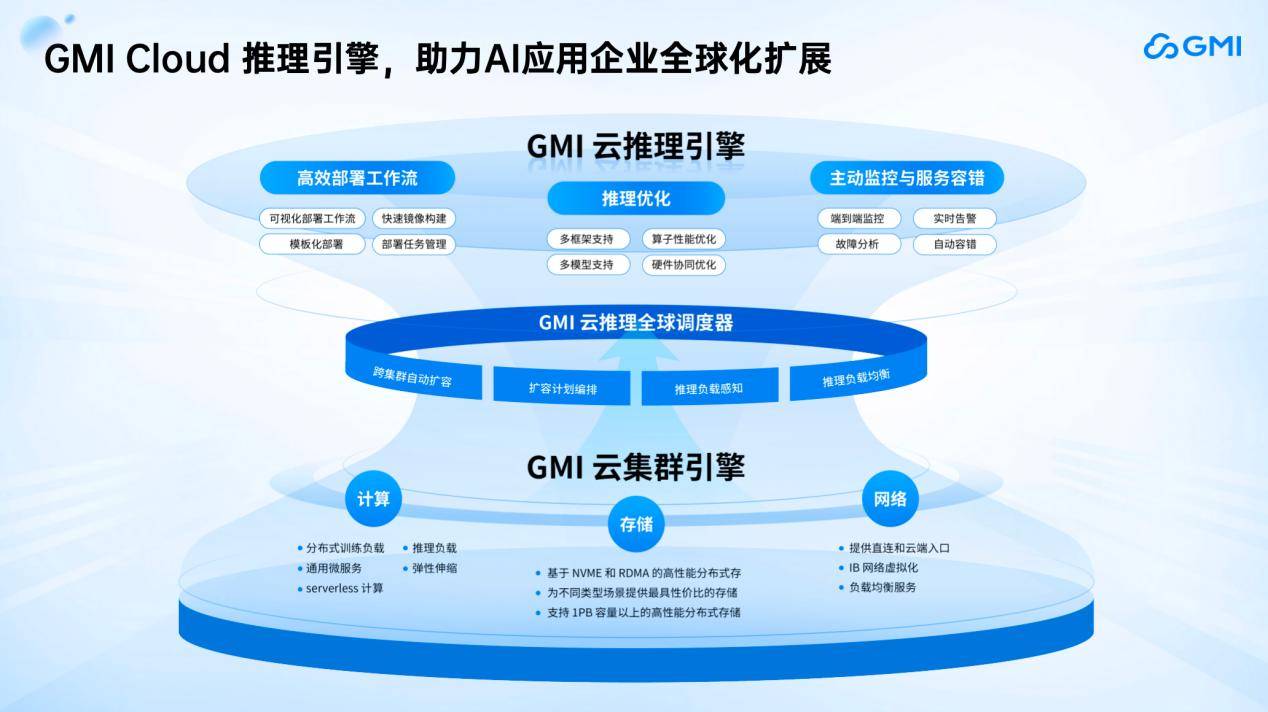

在演讲的尾声,King Cui再次强调了GMI Cloud致力于提供全栈AI基础设施的坚定信念。他表示,Cluster Engine将为企业客户提供高稳定性的模型训练服务,而Inference Engine则致力于助力企业客户的AI应用走向世界。GMI Cloud将以一朵云和两个引擎的高效稳定架构,持续推动AI推理的全球算力革命。