豆包大模型团队近日宣布了一项重要进展,他们成功推出了UI-TARS-1.5,这是一款以视觉-语言模型为核心的多模态智能体,专为在虚拟环境中高效执行任务而设计。该智能体不仅技术先进,而且已经向公众开源。
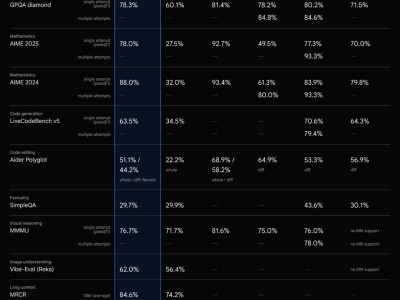
据团队介绍,UI-TARS-1.5在多个GUI图形用户界面评测基准上取得了显著成绩,一举夺得了7个典型评测的SOTA(当前最优)表现。这一突破性的成就充分展示了其强大的处理能力和广泛的应用潜力。
尤为UI-TARS-1.5在游戏中展现出了卓越的长时推理能力。这意味着它能够持续、准确地理解复杂的游戏情境,并作出相应的决策,这对于提升虚拟环境中的交互体验具有重要意义。
该智能体还首次在开放空间中展示了其出色的交互能力。无论是在广阔的虚拟世界还是复杂的现实模拟环境中,UI-TARS-1.5都能够灵活应对,实现高效、流畅的交互体验。
豆包大模型团队表示,UI-TARS-1.5的推出是他们长期致力于人工智能领域研究的重要成果。未来,他们将继续探索和优化这一智能体的性能,以推动其在更多领域的应用和发展。
UI-TARS-1.5的开源也将为开发者们提供一个宝贵的资源,使他们能够基于这一强大的智能体构建更加智能、高效的虚拟环境应用。这无疑将加速人工智能技术在各个领域的发展和应用。