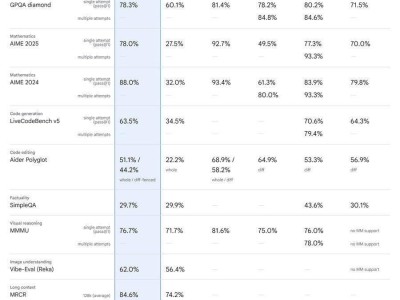
科大讯飞与华为昇腾携手,在“飞星一号”平台上实现了MoE模型集群推理性能的显著提升。这一突破性进展,标志着国产算力在AI领域的应用迈出了重要一步。
据悉,双方联合团队通过一系列创新优化手段,成功将MoE模型在“飞星一号”平台上的集群推理性能翻倍。这一成就不仅彰显了国产算力在处理复杂AI任务方面的潜力,更为AI技术的广泛应用提供了有力支持。
在此次优化过程中,联合团队针对MoE模型的特性,升级了PD分离+大规模专家并行系统解决方案。他们通过定制集合通信协议,有效消除了集合通信流量冲突,解决了推理过程中Prefill阶段和Decode阶段的相互干扰问题。这一创新举措使得P实例和D实例均达到了系统最优状态,性能提升超过20%。
联合团队还在国产算力上实现了MTP多token预测技术,这一技术的引入显著降低了MTP层的计算耗时,整体性能提升超过30%。同时,他们还对专家负载均衡算法进行了升级,实现了多DP负载均衡,卡间负载均衡差异小于8%,集群推理吞吐性能因此提升了30%以上。
联合团队还创新性地实现了异步双发射技术。这一技术有效解决了高并发下的高CPU负载问题,实现了CPU和NPU的高效协同。通过降低服务请求调度耗时,系统性能得到了进一步提升,提升幅度达到10%。
基于上述一系列创新解决方案的迭代与升级,联合团队在“飞星一号”平台上对星火MoE模型、DeepSeekV3/R1进行了实测。测试结果显示,推理性能相较于上一个版本有了显著提升,几乎逼近了国产算力上MoE集群推理的性能上限。这一突破性进展无疑为国产算力在AI领域的应用注入了新的活力。