近日,Character.AI公司在X平台上发布了一项令人瞩目的新技术——AvatarFX模型,该模型能够将静态图片中的人物赋予生命,让他们“开口说话”。这一创新技术引发了广泛关注和讨论。
用户只需上传一张图片,并从平台提供的声音库中选择一个声音,AvatarFX模型就能迅速生成一个会说话、会移动的形象。这些形象不仅动作自然流畅,还能准确地表达情感,真实感令人惊叹。这一技术的实现,得益于Character.AI公司研发的一种名为“SOTA DiT-based diffusion video generation model”的先进AI模型。
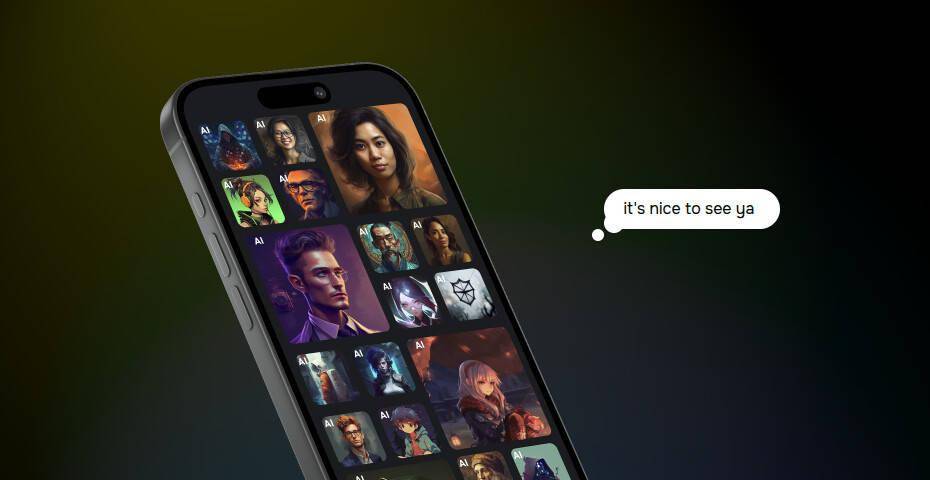
据了解,该模型经过长时间的训练和优化,结合了音频条件优化技术,能够高效地生成高质量的视频内容。为了展示这一技术的实际效果,Character.AI公司还附上了一段演示视频。

AvatarFX模型的技术亮点在于其出色的“高保真、时间一致性”视频生成能力。即使面对复杂的场景,如多角色、长序列或多轮对话,AvatarFX模型也能保持惊人的速度和稳定性,生成的视频内容质量极高。与目前市场上的一些竞争对手,如OpenAI的Sora和Google的Veo相比,AvatarFX模型并非从零开始或基于文本生成视频,而是专注于将特定的静态图片动画化,为用户提供了全新的使用体验。
然而,这一技术的出现也引发了一些潜在的风险和争议。由于AvatarFX模型能够生成高度逼真的虚假视频,用户可能会上传名人或熟人的照片,制作看似真实的对话视频,从而引发隐私和伦理问题。因此,Character.AI公司在推广这一技术的同时,也强调了用户应遵守法律法规,尊重他人的隐私和权益。