近日,meta公司震撼发布了其最新研发的Llama 4系列大模型,包括Llama 4 Scout、Llama 4 Maverick和Llama 4 Behemoth三款产品,这一消息迅速在人工智能领域掀起了波澜。据meta透露,这些模型经过海量未标注文本、图像及视频数据的训练,视觉理解能力实现了质的飞跃,仿佛在大模型领域独领风骚。
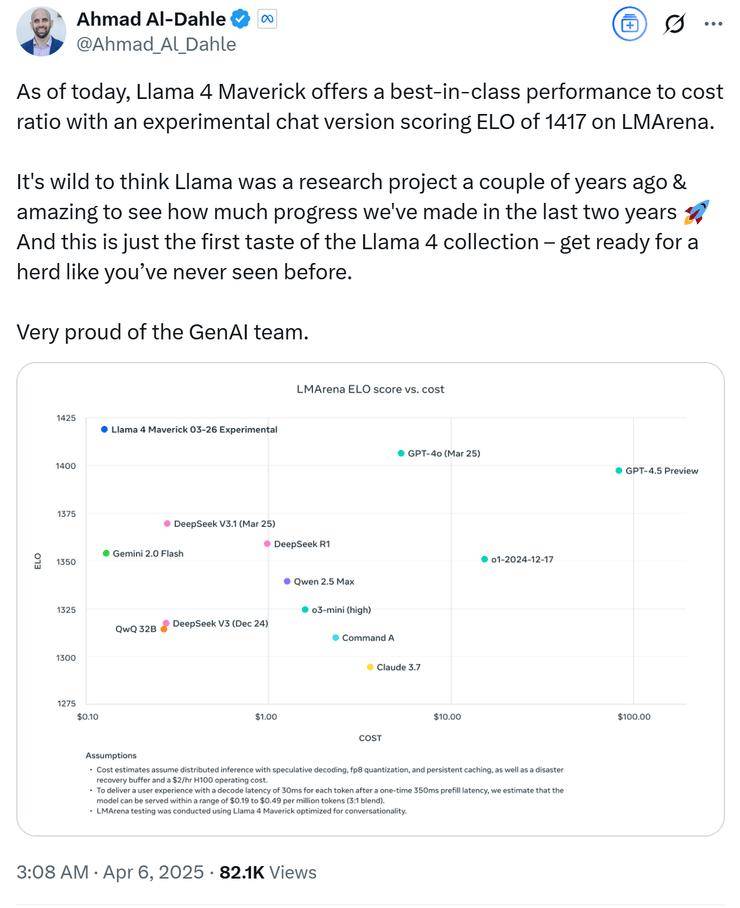
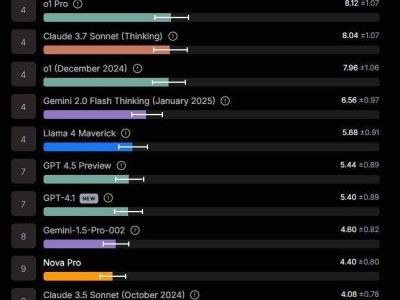
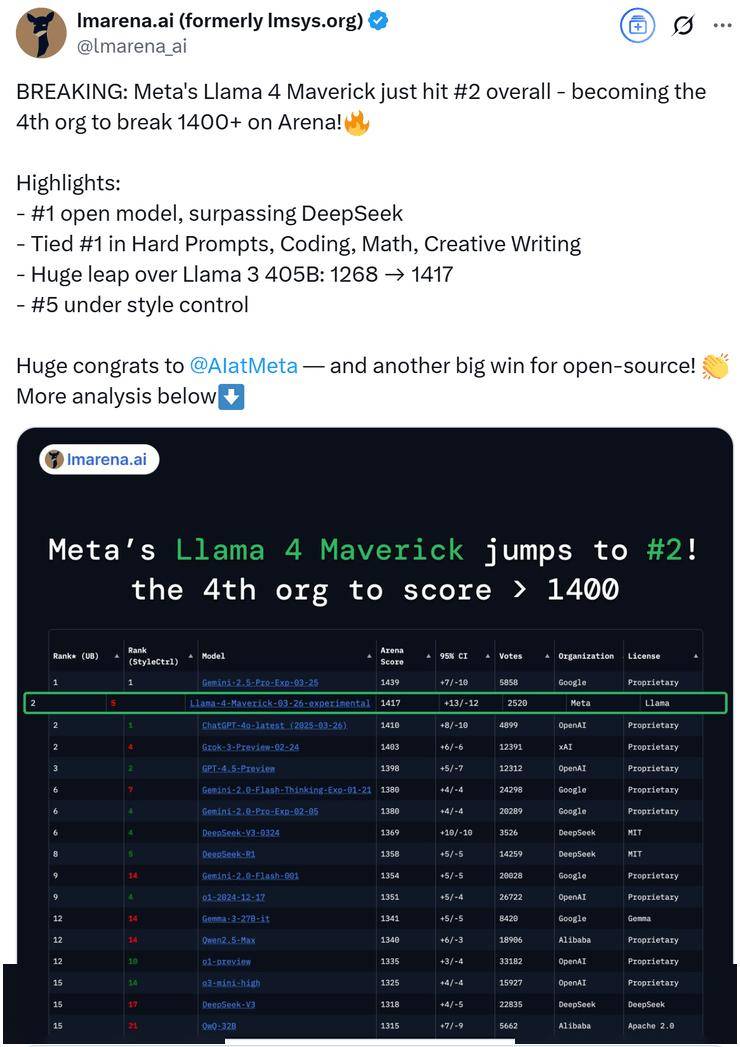
meta GenAI部门负责人Ahmad Al-Dahle自信地表示,他们的开放系统将能够产出最优的小型、中型以及前沿大模型,并附上了一张Llama 4的性能对比测试图。在这张图表中,Llama 4 Maverick的排名迅速攀升至第二位,成为第四个突破1400分的大模型,并在开放模型排行榜上超越了DeepSeek,坐上了头把交椅。
然而,就在Llama 4系列备受赞誉之际,一些细心的网友却发现了一些问题。他们通过让模型直接生成几何程序的方式对Llama 4进行测试,结果却发现,在绘制包含受重力影响球的六角形集合图像时,Llama 4连续8次尝试均告失败,而DeepSeek R1和Gemini 2.5 Pro则一次成功。这一发现引发了网友们的广泛讨论和质疑。

不少网友对Llama 4的表现感到失望,认为新版本模型在性能上并未取得显著突破,反而在某些测试中表现不如现有大模型。甚至有网友将Llama 4系列的能力与其他模型进行了对比,认为Llama 4 Maverick的402B大模型与Qwen QwQ 32B的写代码水平相当,而Llama 4 Scout则接近于Grok2或文心4.5的水平。

随着网友们的深入测试,更多关于Llama 4的问题逐渐浮出水面。有网友发现,在官方数据中表现卓越的Llama 4,在实际测试中却频频失利。这引发了网友们对meta是否存在刷榜行为的怀疑。经过多方证实,网友们发现,在Ahmad Al-Dahle发布的Llama性能对比测试图的最下方,有一行小字注明“Llama 4 Maverick针对对话进行了优化”,而meta早已为自己留下了“图片仅供参考”的余地。
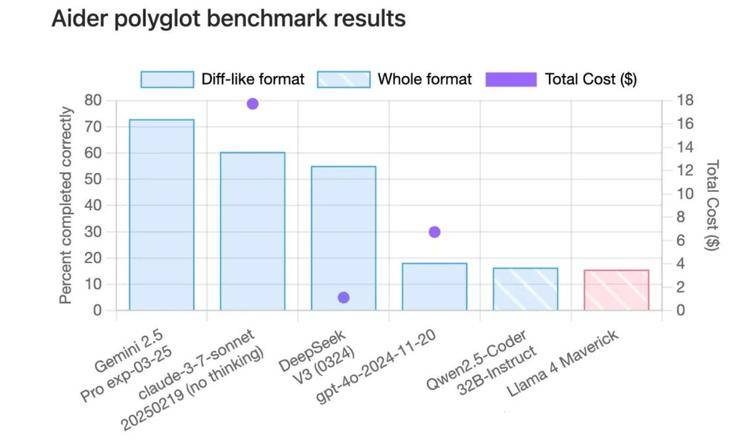
网友们纷纷带着Llama 4参与各大测试榜单,结果在code测试榜单Aider ployglot中,Llama 4的得分甚至低于qwen-32B。在另一个代码评测榜单中,Llama 4的成绩也只能排在中间位置。在EQBench测评基准的长文章写作榜上,Llama 4系列更是直接垫底。即便是最基础的翻译任务,Llama 4的表现也不尽如人意,甚至不如Gemma 3的27B模型。
更令人震惊的是,一则发布在海外求职平台的信息透露,Llama 4的训练存在严重问题,内部模型的表现远未达到开源SOTA水平,而Llama 4的高分很可能是领导层为了交差而做出的“努力”。这一爆料很可能来自meta公司内部,进一步加剧了网友们的质疑。
此次Llama 4的翻车事件不仅让网友们对meta的技术实力产生了怀疑,更让meta失去了社区的信任和支持。在人工智能领域,技术创新和诚信是至关重要的。meta如果想要在激烈的市场竞争中站稳脚跟,就必须摒弃急功近利的心态,专注于技术创新和用户体验的提升。