昆仑万维在人工智能领域再次迈出重要一步,正式推出了Skywork-R1V 2.0,这一全新升级的多模态推理模型,标志着多模态思考新时代的进一步深化。自去年3月18日首次开源Skywork-R1V以来,昆仑万维不断深耕技术,如今,R1V 2.0的问世,无疑为行业树立了新的技术标杆。
R1V 2.0作为当前最均衡兼顾视觉与文本推理能力的开源多模态模型,其在高考理科难题的深度推理与通用任务场景中均展现出了卓越的性能。该模型不仅在理科学科题目(数学、物理、化学)的推理上效果拔群,为用户提供了一个免费的AI解题助手,更在38B权重和技术报告上全面开源,极大地推动了多模态生态的建设与发展。
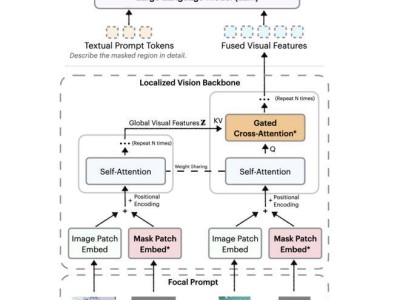
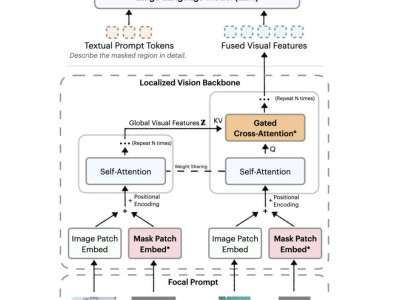
技术上的创新是R1V 2.0的一大亮点。模型引入了多模态奖励模型Skywork-VL Reward与混合偏好优化机制MPO,这些创新技术全面提升了模型的泛化能力。同时,选择性样本缓冲区机制SSB的引入,也成功突破了强化学习中“优势消失”的瓶颈。这些技术上的突破,使得R1V 2.0在多个权威基准测试中,相较于前代R1V 1.0,在文本与视觉推理任务中均实现了显著的性能跃升。
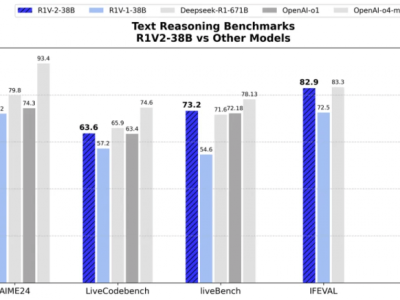
在MMMU测试中,R1V 2.0取得了73.6分,刷新了开源SOTA纪录;在Olympiad Bench上,模型更是达到了62.6分,显著领先其他开源模型。在MathVision、MMMU-PRO与MathVista等多项视觉推理榜单中,R1V 2.0也均表现出色,其多项能力已可媲美闭源商业模型,成为当前开源多模态推理模型中的佼佼者。在与开源多模态模型的对比中,R1V 2.0的视觉推理能力更是脱颖而出。
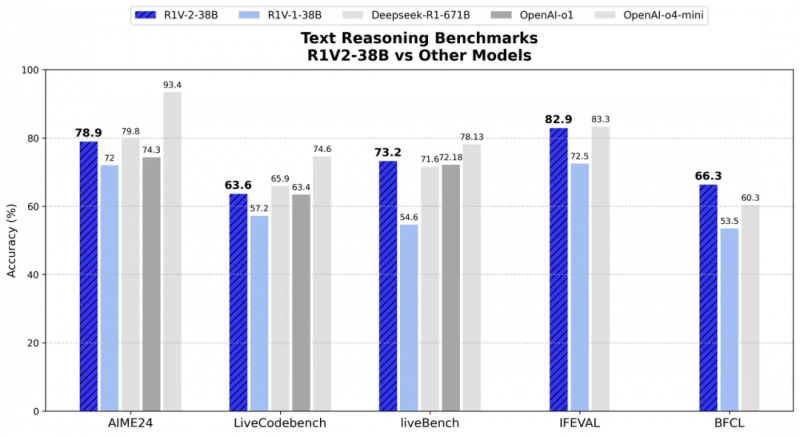
在文本推理方面,R1V 2.0同样展现出了非凡的实力。在AIME2024和LiveCodeBench等挑战中,模型分别取得了78.9分和63.6分,展现出了人类专家级的数学与代码理解能力。在与专用文本推理模型的对比中,R1V 2.0同样不落下风,其卓越的文本推理能力得到了充分验证。
昆仑万维团队在R1V 2.0的开发过程中,充分吸收了全球开发者与研究者的反馈,针对模型推理能力的提升与通用能力的保持进行了深入研究。为实现多模态大模型在“深度推理”与“通用能力”之间的最佳平衡,R1V 2.0引入了全新的多模态奖励模型Skywork-VL Reward及规则驱动的混合强化训练机制。这一创新不仅显著增强了模型的推理能力,更稳固了模型在多任务、多模态场景中的稳定表现与泛化能力。
Skywork-VL Reward模型的推出,为通用视觉语言模型(VLM)提供了高质量奖励信号,精准评估了多模态推理模型长序列输出的整体质量,同时也作为并行线上推理最优答案选择的利器,极大地促进了多模态模型的协同发展。在视觉奖励模型评测榜单VL-RewardBench中,Skywork-VL Reward取得了73.1的SOTA成绩,同时在纯文本奖励模型评测榜单RewardBench中也斩获了高达90.1的优异分数,全面展示了其在多模态和文本任务中的强大泛化能力。
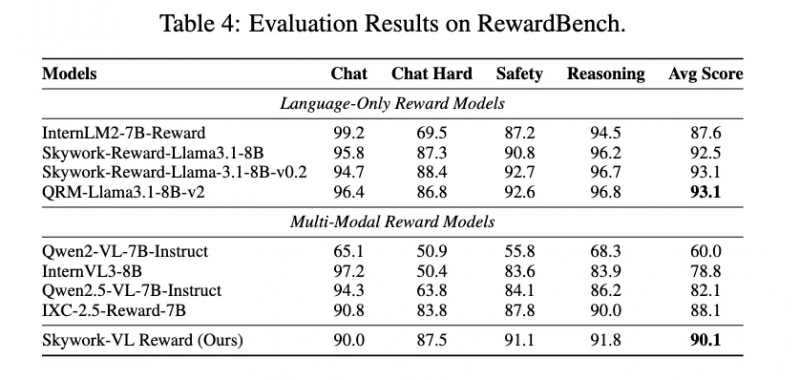
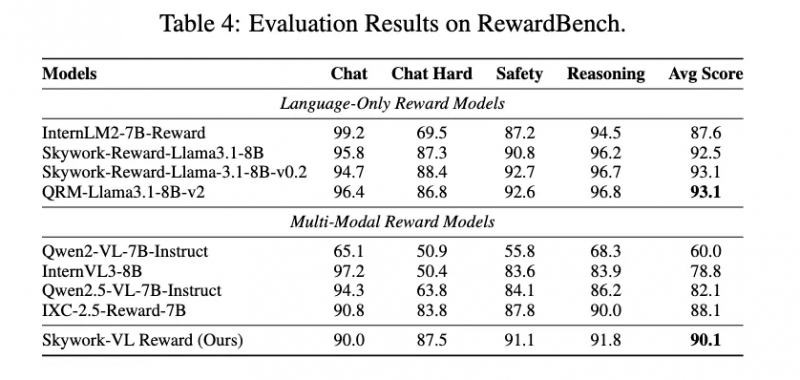
为回馈社区和行业,昆仑万维团队将Skywork-VL Reward完整开源,这一举措无疑将进一步推动多模态强化学习的发展。R1V 2.0还引入了MPO机制和基于规则的群体相对策略优化GRPO方法,通过同组候选响应之间的相对奖励比较,引导模型学会更精准的选择和推理路径,进一步提升了模型的推理能力。
R1V 2.0的诞生,不仅推动了开源多模态大模型在能力边界上的突破,更为多模态智能体的搭建提供了新的基座模型。昆仑万维在人工智能领域的持续深耕和创新,无疑将为行业的未来发展注入更多活力与可能。