在今日于武汉盛大举行的百度Create开发者大会上,百度创始人兼首席执行官李彦宏向业界揭开了两款全新大模型的神秘面纱——文心大模型4.5 Turbo与文心大模型X1 Turbo。这一重大发布,标志着百度在人工智能领域的又一里程碑式进展。
李彦宏指出,当前市场上诸如DeepSeek等模型虽备受瞩目,但仍面临模态局限、幻觉率高、运行速度慢及成本高昂等挑战。为应对这些难题,百度精心打造了这两款Turbo版大模型,旨在以更强大的性能满足开发者需求。
在演讲中,李彦宏分享了AI行业的最新动态,提到DeepSeek的崛起促使MCP(模型上下文协议)逐渐成为行业标准,代码智能体、通用智能体等多智能体协作产品也日益受到关注。然而,随着模型迭代加速,开发者群体中也弥漫着焦虑情绪。他们担心自己基于大模型开发的应用迅速过时,失去市场竞争力。李彦宏坦言,这种担忧并不无道理,因为大模型领域的竞争异常激烈,几乎每周都有新产品发布。
“开发者们正面临一把双刃剑。”李彦宏强调,“一方面,他们需要紧跟技术趋势,避免陷入大模型发展的盲区;另一方面,日益强大的模型能力也为开发者提供了更多选择,关键在于找准应用场景,选择合适的基础模型。”他进一步指出,AI应用才是创造真正价值的所在,没有应用,模型和芯片都将失去意义。
回顾李彦宏过往的言论,他曾多次批评中国大模型数量过多但使用量有限,认为“百模大战”是对社会资源的极大浪费,应更多关注超级应用的开发。他还指出,包括百度在内的大公司在面对快速变化的市场时反应迟钝,生产力落后。对于开源与闭源模型的争议,李彦宏态度鲜明,认为开源模型在商业领域没有优势,闭源模型如ChatGPT和文心一言等更为强大且成本更低。
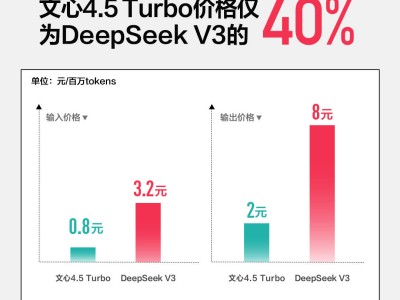
在此次大会上,李彦宏详细介绍了全新发布的文心大模型4.5 Turbo和文心大模型X1 Turbo。相较于文心4.5,Turbo版在速度上有了显著提升,价格更是下降了80%。具体而言,每百万tokens的输入价格仅为0.8元,输出价格为3.2元,仅为DeepSeek-V3的40%。而文心大模型X1 Turbo的价格更为亲民,输入价格为1元/百万tokens,输出价格为4元/百万tokens,仅为DeepSeek R1调用价格的25%。

百度还展示了基于昆仑芯三代P800的中国首个全自研3万卡集群。李彦宏自豪地表示,该集群能够同时承载多个千亿参数大模型进行全量训练,并支持1000个客户进行百亿参数大模型的精调。
演讲接近尾声时,李彦宏满怀信心地表示:“现在,在中国开发应用,我们有底气。我坚信,应用创造未来,开发者创造未来。”这一番话,无疑为在场的开发者们注入了强大的信心和动力。