英伟达近期在数学推理领域迈出了重要一步,推出了两款专为解决复杂数学问题设计的先进AI模型——OpenMath-Nemotron-32B和OpenMath-Nemotron-14B-Kaggle。
长久以来,数学推理一直是AI技术难以攻克的难题。尽管传统的语言模型在生成自然语言文本方面表现出色,但在面对需要深入理解抽象概念和进行多步骤逻辑推导的数学问题时,却常常力不从心。为了解决这一挑战,英伟达精心打造了这两款新模型。
OpenMath-Nemotron-32B作为系列中的佼佼者,拥有高达328亿的参数,并采用了BF16张量运算来优化硬件效率。这款旗舰模型在多项基准测试中,如AIME 2024、AIME 2025和HMMT 2024-25,均取得了令人瞩目的成绩。特别是在工具集成推理(TIR)模式下,它在AIME24上的pass@1准确率高达78.4%,通过多数投票机制后,这一准确率更是飙升至93.3%。
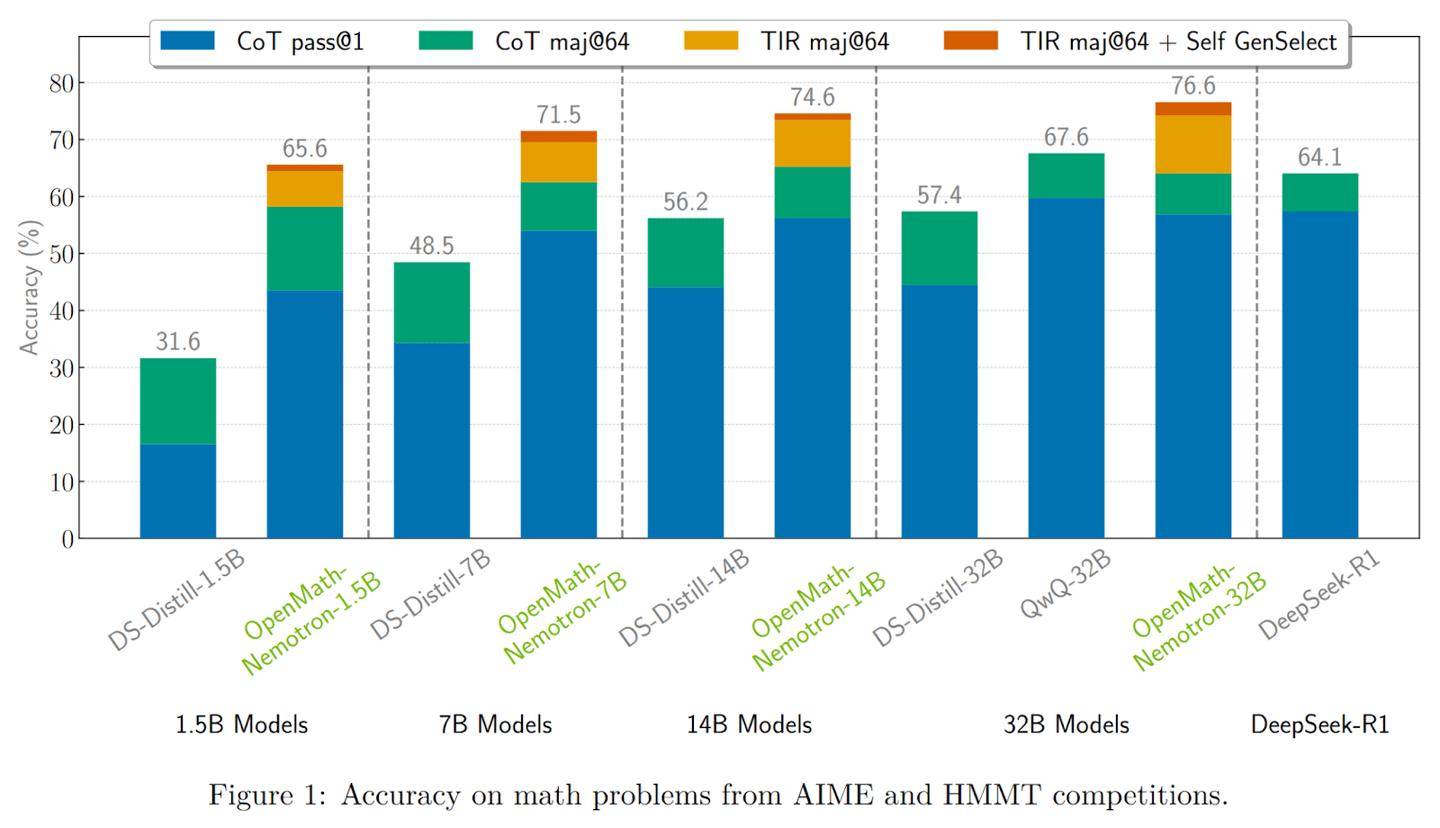
除了强大的性能,OpenMath-Nemotron-32B还提供了多种推理模式以满足不同需求。用户可以选择链式思维(CoT)、工具集成推理(TIR)和生成式选择(GenSelect)三种模式,根据科研或生产环境的具体场景,平衡推理的透明度和答案的精确度。
另一款模型,OpenMath-Nemotron-14B-Kaggle,则是一款更为轻量级的解决方案。它拥有148亿参数,专为AIMO-2 Kaggle竞赛优化设计。通过精选OpenMathReasoning数据集的子集进行微调,这款模型成功夺得了竞赛的桂冠。在AIME24测试中,它在CoT模式下的pass@1准确率为73.7%,而在GenSelect模式下则提升至86.7%。这款模型在保持高质量数学解题能力的同时,更适合资源受限或需要低延迟的场景。
英伟达为这两款模型提供了完整的开源管道,集成于NeMo-Skills框架中。这意味着开发者可以轻松地通过示例代码构建应用,获取逐步解答或简洁答案。模型还针对NVIDIA的GPU,如Ampere和Hopper架构,进行了深度优化。利用CUDA库和TensorRT技术,模型能够高效运行。同时,Triton Inference Server的支持确保了低延迟、高吞吐量的部署,而BF16格式则在内存占用与性能之间取得了完美的平衡。
这两款新模型的推出,标志着英伟达在数学推理领域取得了重大突破。它们不仅为科研和生产环境提供了强大的工具,也为AI技术的发展开辟了新的道路。