近日,灵初智能宣布了一项重大技术突破,推出了名为Psi-R1的分层端到端VLA+强化学习算法模型。该模型引入了Chain of Action Thought(CoAT)框架,使得机器人在开放环境中能够进行自主推理决策,并完成一系列复杂的长程操作。
为了展示Psi-R1的能力,灵初智能选择了一个极具挑战性的场景——麻将。在这个游戏中,机器人不仅需要理解复杂的游戏规则,还需要根据不断变化的牌局和对手行为来制定动态策略。机器人还需要完成精确的抓牌、出牌和理牌等动作,这对机器人的灵巧操作能力和长程规划提出了极高要求。

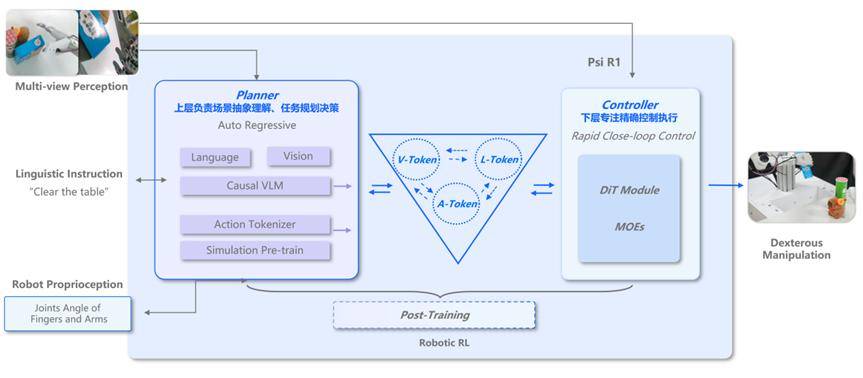
在演示视频中,Psi-R1展现了令人惊叹的能力。机器人能够准确地翻牌、碰杠,并根据牌局状况动态调整策略。它甚至还能与其他机器人进行协作,通过信息共享和配合递牌来提升胜率。这些能力的实现,得益于Psi-R1模型中的慢脑输入系统,该系统包含了行动Token,从而构建了首个支持「动作感知-环境反馈-动态决策」全闭环的VLA模型。

Psi-R1模型的慢脑S2专注于推理规划,将S1的操作进行tokenize后作为输入,与语言和视觉模态进行融合。基于Causal VLM自回归架构,Psi-R1实现了多模态融合的推理和任务规划,从而能够完成复杂的长程任务。快慢脑之间通过Action Tokenizer隐式连接,协同工作,使得机器人在麻将游戏中表现出色。
除了麻将游戏外,Psi-R1模型还具有广泛的应用前景。在泛工业领域,它可以用于来料仓检测和成品包装等场景;在零售物流领域,它可以应用于拣选、分拨、补货和打包等环节;在家庭服务与协作场景中,Psi-R1也展现出巨大的潜力。

目前,灵初智能已与多家制造业、商超零售和跨境物流等行业的龙头企业展开合作,共同探索Psi-R1模型的高价值商业化应用。从泛工业到泛零售物流,再到家庭应用,灵初智能正梯次布局,逐步推动Psi-R1模型在各个领域的应用落地。
随着技术的不断发展和应用场景的不断拓展,Psi-R1模型有望为机器人领域带来更多的创新和突破。