在人工智能的浩瀚宇宙中,一个名为VLA(视觉-语言-动作)的新星域在2018年悄然升起,这一变革性的领域由澳大利亚机器人视觉研究中心(ACRV)的博士后研究员吴琦及其团队率先点亮。吴琦,这位在学术界屡获殊荣的科学家,与中国计量大学、英国巴斯大学及澳大利亚阿德莱德大学有着深厚的学术渊源,他的研究足迹遍布图像描述、视觉问答,并最终引领至VLA的广阔天地。
2018年,吴琦与博士生Peter Anderson及Abhishek Das在CVPR 2018上首次将视觉-语言(VL)与机器人导航相结合,发表了VLN(视觉-语言-导航)的开山之作。紧接着,Abhishek Das的“EmbodiedQA(具身问答)”研究更是让“Embodied”概念深入人心。同年,NLP领域的顶级会议ACL在墨尔本召开,吴琦团队借此机会举办了一场题为“将语言和视觉与动作联系起来”的tutorial,正式拉开了VLA研究的序幕。
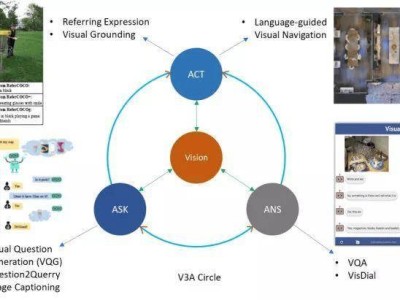
在这场tutorial中,吴琦团队不仅分享了CNN、RNN等基础方法,还深入探讨了机器人数据、环境仿真器以及强化学习在VLA研究中的应用。吴琦意识到,要使机器真正解决实际问题,除了学习和理解多模态信息外,还需与真实环境进行交互。因此,他在原有的VL基础上加入了“动作(Action)”,提出了“V3A”概念,即视觉(Vision)、提问(Ask)、回答(Answer)和行动(Act)。

吴琦的学术生涯充满了前瞻性和创新性。早在MS COCO数据集发布之初,他便敏锐地捕捉到了图像描述方向的研究潜力,并迅速跟进。随后,他又在视觉问答(VQA)新方向上发表了“Ask Me Anything”工作。七年间,VLA从最初的萌芽状态发展成为具身智能领域内的热门话题,吸引了全球科研人员的广泛关注。英伟达、Figure AI、Physical Intelligence及清华大学等国内外知名机构纷纷推出了各自的VLA模型。

作为VLA领域的开拓者,吴琦并未止步于理论探索,而是选择在VLN方向上继续深耕,并着手进行真机研究。如今,他已在澳大利亚阿德莱德大学担任副教授,领导着“V3A Lab”实验室,并在澳大利亚机器学习研究中心(AIML)担任视觉与语言研究方向的实验室主任。在谈到具身智能与VLA时,吴琦表示,VLA不应局限于上半身的操作任务,导航问题仍有待突破。
回顾VLA的发展历程,吴琦团队的工作无疑起到了关键作用。他们不仅提出了R2R数据集和任务,还推动了VLN研究的兴起。随后,王鑫在CVPR 2019上利用模仿学习和强化学习解决VLN的工作更是让这一领域大放异彩。而GPT系列的出现则进一步加速了VLA的发展,解决了许多VL难以解决的问题,为VLA的研究奠定了坚实基础。

在吴琦看来,VLA的大热是产业和学术发展的双重结果。从产业视角来看,任何落地场景都需要处理多模态输入,并依赖一个高水平的推理模型辅助完成复杂的规划与行为决策。而从学术研究趋势而言,自然语言处理(NLP)与计算机视觉(CV)领域的核心任务已取得显著进展,研究者正积极探索新的前沿方向。VLA领域的研究者需要精准定位应用场景,弄清楚语言(L)的核心价值,即为机器人提供一种更简便的人机交互方式。
对于导航的难点和重要性,吴琦有着深刻的认识。他认为,视觉导航作为任务本身可能并不复杂,但视觉语言导航(VLN)却极具挑战性。VLN能够实现根据指令导航到指定位置并完成特定任务的功能,这在过去是无法想象的。而VLA中的action则更加广泛,VLN只是其中一个子集。吴琦强调,家用场景下的导航问题尤为复杂,需要机器人不断移动并处理动态场景中的挑战。

在VLA领域的研究中,数据问题一直是制约发展的关键因素之一。吴琦认为,虽然数据是最大的难题,但同时也是最容易突破的。他提出了多种技术路径来解决数据问题,包括真人操控采集、Sim2Real模拟生成以及视频数据驱动等。同时,他也强调了模拟器在VLA研究中的重要性,认为模拟器需要大厂来推动发展,并具备场景仿真、物理仿真和高效运行等关键特性。
随着具身智能的不断发展,VLA领域的研究将越来越深入。吴琦表示,他将继续在VLN方向上扎根,并着手进行更多真机研究,以推动VLA技术的实际应用和落地。他的工作不仅为VLA领域的发展奠定了坚实基础,也为人工智能的未来探索提供了无限可能。