在科技巨头纷纷推出最新大语言模型的4月,阿里巴巴于4月29日凌晨正式揭晓了其压轴之作——Qwen3系列。这款大模型的问世,不仅标志着阿里巴巴在AI领域的又一次重大突破,还为其在全球开发者社区中赢得了广泛关注。
本月早些时候,meta、字节跳动、OpenAI、Google及百度等科技巨头已相继推出了各自的大模型产品。其中,OpenAI更是一口气推出了三款,而百度在Create 2025 AI开发者大会上亦发布了两款新品。面对如此激烈的竞争环境,阿里巴巴的Qwen3系列能否带来新意,成为了业界关注的焦点。
事实证明,Qwen3系列确实不负众望。作为阿里巴巴旗舰级的大模型产品,它不仅延续了开源路线,还在模型性能上取得了显著提升,进一步缩小了与顶尖大模型之间的差距。更令人瞩目的是,Qwen3系列还是一款混合推理模型,支持思考模式和非思考模式,这一创新设计使其在众多大模型中脱颖而出。

混合推理模型的概念并非首次提出,但Qwen3系列却是国内首个真正落地并完全开源的混合推理模型。在全球范围内,除Claude-3.7-Sonnet和Google近期推出的Gemini 2.5 Flash外,鲜有类似尝试。OpenAI虽然也表明了“混合推理”的目标,但仍在开发中。Qwen3系列的这一创新设计,无疑为其赢得了更多关注。
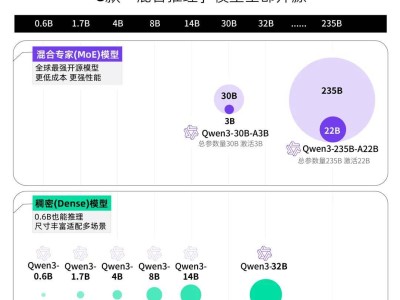
Qwen3系列还是一个多尺寸的系列模型,涵盖了从0.6B到32B的六个稠密模型,以及适用于复杂任务的MoE混合专家模型Qwen3-30B-A3B和Qwen3-235B-A22B。这些模型全部支持119种语言和方言,为用户和开发者提供了更多选择。
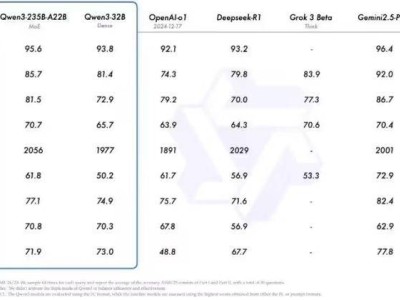
在性能表现上,Qwen3系列同样不负众望。阿里巴巴宣称,小模型如Qwen3-4B的性能已可媲美上一代的Qwen2.5-72B-Instruct。而MoE模型更是在基准测试上表现出了媲美顶尖闭源模型的能力。尤其是在数学推理基准AIME25上,Qwen3-235B-A22B得分达到81.5,刷新了开源模型的纪录。
然而,Qwen3系列也并非十全十美。在实际推理表现上,Qwen3-235B-A22B在面对复杂问题时仍显得力不从心。有时即便在满血状态下,也容易陷入冗长而无用的推理中,导致最终结果不理想。这一点在雷科技的测试中得到了体现,Qwen3-235B-A22B在面对某些问题时,思考太久且不断重复方向,甚至未能抓住关键信息。

尽管如此,Qwen3系列的推出仍然为阿里巴巴在AI战略上带来了重要补强。过去两年里,阿里巴巴在大模型领域的布局虽然不算慢,但始终未能真正站到最前排。Qwen3系列的推出,不仅提升了阿里巴巴在开源生态中的存在感,还为其在AI商业化竞争中增强了筹码。
从商业化的角度来看,Qwen3系列直接回应了当前模型商业应用的两大痛点:推理成本高以及灵活适配性不足。通过引入MoE架构大幅降低推理成本,同时又在推理机制上支持思考与非思考的灵活切换,Qwen3系列在推理效率与推理成本之间找到了相对平衡的位置。

对于阿里巴巴来说,Qwen3系列的推出不仅是一次技术上的升级,更是一次战略上的重要布局。它不仅能够提升阿里巴巴在AI领域的竞争力,还能够为其在AI商业化方向上带来新的机遇。随着大模型竞争的加剧,性能和成本将成为两条重要主线。阿里巴巴能否继续保持节奏,甚至在未来占据主动,仍需更多技术演进和产品落地来检验。